ATR Gauge - Audiophile StyleThe ATR Gauge - Audiophile Style indicator is a custom visualization tool. It's designed to give you a quick, retro-inspired snapshot of market volatility using the Average True Range (ATR) metric. Think of it as a dashboard widget styled like the VU meters on old-school audiophile equipment (e.g., vintage stereo amps from brands like McIntosh or Marantz)—simple, elegant, and functional. It sits in one of the corners of your chart and helps you gauge how "hot" or "cool" the current price action is compared to recent levels.
Why This Gauge?: Standard ATR plots as a line on your chart, but this turns it into a visual "meter" focused on the last 24 hours. It's like a speedometer for volatility—quick to read at a glance. Useful for day traders, scalpers, or anyone monitoring intraday risk without cluttering the main chart.
Statistics

Match on Selectable Percentage Change + RangeIndicator Overview:
Match on Selectable Percentage Change + Range is a powerful analytical tool designed for traders and analysts who want to identify historical price bars that match a specific percentage variation, and then evaluate how price evolved in the following days. It combines precision filtering with visual tabular feedback, making it ideal for pattern recognition, backtesting, and scenario analysis.
What It Does
This indicator scans historical bars to find instances where the percentage change between two consecutive closes matches a user-defined target (± a customizable tolerance). Once matches are found, it displays:
The date of each match (most recent first)
The actual variation searched
The percentage change after 2, 10, 20, and 30 bars
The min-max range (in %) over those same periods
All results are shown in a dynamic table directly on the chart.
Inputs & Controls
Input Description
Which variation do you want to analyze? (%)
Set the target percentage change to look for (e.g. 2.5%)
% deviation from the variation to be considered (%) Define the tolerance range around the target (e.g. ±0.5%)
Bars to analyze (max 9999) Set how many past bars to scan
Show match table Toggle to enable/disable the entire table
Show percentage variations (2d, 10d, 20d, 30d) Toggle to show/hide post-match percentage changes
Show min-max ranges (2d, 10d, 20d, 30d) Toggle to show/hide post-match high/low ranges
Table Structure
Each row in the table represents a historical match. Columns include:
Date: When the match occurred
Variation in: The actual % change that triggered the match
2d / 10d / 20d / 30d: % change after those days
Min-Max 2d / 10d / 20d / 30d: Range of price movement after those days
Color coding helps quickly identify bullish (green) vs bearish (red) outcomes.
Use Cases
Backtesting: See how similar past moves evolved over time
Scenario modeling: Estimate potential outcomes after a known variation
Pattern recognition: Spot recurring setups or volatility clusters
Risk analysis: Understand post-variation drawdowns and upside potential
Tips for Use
Use tighter deviation (e.g. 0.3%) for precision, or wider (e.g. 1%) for broader pattern capture.
Combine with other indicators to validate setups (e.g. volume, RSI, trend filters).
Toggle off variation or range columns to focus only on the metrics you need.

Gold–Bitcoin Correlation (Offset Model) by KManus88This indicator analyzes the correlation between Gold (XAU/USD) and Bitcoin (BTC/USD) using a time-offset model adjustable by the user.
The goal is to detect cyclical leads or lags between both assets, highlighting how capital flows into Gold may precede or follow movements in the crypto market.
Key Features:
Dynamic correlation calculation between Gold and Bitcoin.
Adjustable offset in days (default: 107) to fine-tune the temporal shift.
Automatic labels and on-chart visualization.
Compatible with multiple timeframes and logarithmic scales.
Interpretation:
Positive correlation suggests synchronized trends between both assets.
Negative correlation signals divergence or rotation of liquidity.
The time-offset parameter helps estimate when a shift in Gold could later reflect in Bitcoin.
Recommended use:
For macro-financial and global liquidity cycle analysis.
As a complementary tool in cross-asset momentum strategies.
© 2025 – Developed by KManus88 | Inspired by monetary correlation studies and global liquidity cycles.
This script is for educational purposes only and does not constitute financial advice.
Smooth Theil-SenI wanted to build a Theil-Sen estimator that could run on more than one bar and produce smoother output than the standard implementation. Theil-Sen regression is a non-parametric method that calculates the median slope between all pairs of points in your dataset, which makes it extremely robust to outliers. The problem is that median operations produce discrete jumps, especially when you're working with limited sample sizes. Every time the median shifts from one value to another, you get a step change in your regression line, which creates visual choppiness that can be distracting even though the underlying calculations are sound.
The solution I ended up going with was convolving a Gaussian kernel around the center of the sorted lists to get a more continuous median estimate. Instead of just picking the middle value or averaging the two middle values when you have an even sample size, the Gaussian kernel weights the values near the center more heavily and smoothly tapers off as you move away from the median position. This creates a weighted average that behaves like a median in terms of robustness but produces much smoother transitions as new data points arrive and the sorted list shifts.
There are variance tradeoffs with this approach since you're no longer using the pure median, but they're minimal in practice. The kernel weighting stays concentrated enough around the center that you retain most of the outlier resistance that makes Theil-Sen useful in the first place. What you gain is a regression line that updates smoothly instead of jumping discretely, which makes it easier to spot genuine trend changes versus just the statistical noise of median recalculation. The smoothness is particularly noticeable when you're running the estimator over longer lookback periods where the sorted list is large enough that small kernel adjustments have less impact on the overall center of mass.
The Gaussian kernel itself is a bell curve centered on the median position, with a standard deviation you can tune to control how much smoothing you want. Tighter kernels stay closer to the pure median behavior and give you more discrete steps. Wider kernels spread the weighting further from the center and produce smoother output at the cost of slightly reduced outlier resistance. The default settings strike a balance that keeps the estimator robust while removing most of the visual jitter.
Running Theil-Sen on multiple bars means calculating slopes between all pairs of points across your lookback window, sorting those slopes, and then applying the Gaussian kernel to find the weighted center of that sorted distribution. This is computationally more expensive than simple moving averages or even standard linear regression, but Pine Script handles it well enough for reasonable lookback lengths. The benefit is that you get a trend estimate that doesn't get thrown off by individual spikes or anomalies in your price data, which is valuable when working with noisy instruments or during volatile periods where traditional regression lines can swing wildly.
The implementation maintains sorted arrays for both the slope calculations and the final kernel weighting, which keeps everything organized and makes the Gaussian convolution straightforward. The kernel weights are precalculated based on the distance from the center position, then applied as multipliers to the sorted slope values before summing to get the final smoothed median slope. That slope gets combined with an intercept calculation to produce the regression line values you see plotted on the chart.
What this really demonstrates is that you can take classical statistical methods like Theil-Sen and adapt them with signal processing techniques like kernel convolution to get behavior that's more suited to real-time visualization. The pure mathematical definition of a median is discrete by nature, but financial charts benefit from smooth, continuous lines that make it easier to track changes over time. By introducing the Gaussian kernel weighting, you preserve the core robustness of the median-based approach while gaining the visual smoothness of methods that use weighted averages. Whether that smoothness is worth the minor variance tradeoff depends on your use case, but for most charting applications, the improved readability makes it a good compromise.

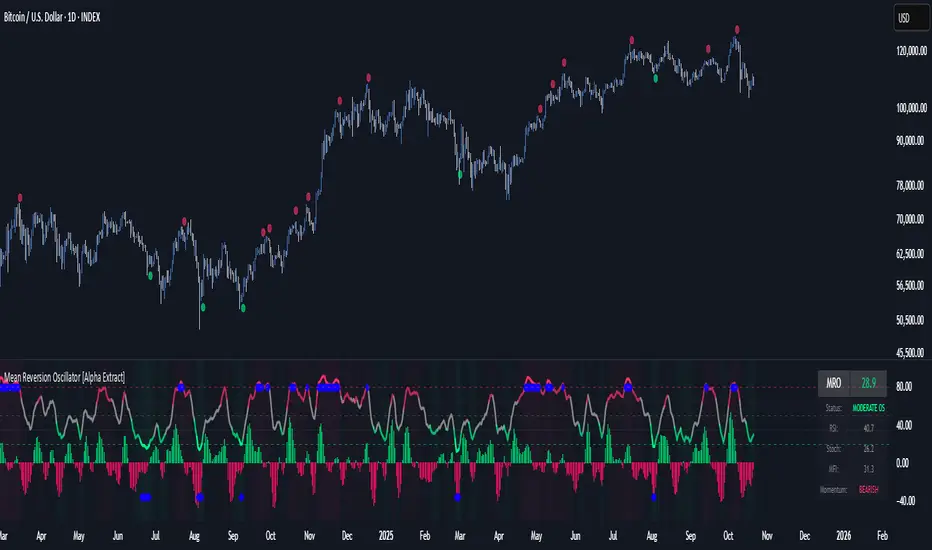
Mean Reversion Oscillator [Alpha Extract]An advanced composite oscillator system specifically designed to identify extreme market conditions and high-probability mean reversion opportunities, combining five proven oscillators into a single, powerful analytical framework.
By integrating multiple momentum and volume-based indicators with sophisticated extreme level detection, this oscillator provides precise entry signals for contrarian trading strategies while filtering out false reversals through momentum confirmation.
🔶 Multi-Oscillator Composite Framework
Utilizes a comprehensive approach that combines Bollinger %B, RSI, Stochastic, Money Flow Index, and Williams %R into a unified composite score. This multi-dimensional analysis ensures robust signal generation by capturing different aspects of market extremes and momentum shifts.
// Weighted composite (equal weights)
normalized_bb = bb_percent
normalized_rsi = rsi
normalized_stoch = stoch_d_val
normalized_mfi = mfi
normalized_williams = williams_r
composite_raw = (normalized_bb + normalized_rsi + normalized_stoch + normalized_mfi + normalized_williams) / 5
composite = ta.sma(composite_raw, composite_smooth)
🔶 Advanced Extreme Level Detection
Features a sophisticated dual-threshold system that distinguishes between moderate and extreme market conditions. This hierarchical approach allows traders to identify varying degrees of mean reversion potential, from moderate oversold/overbought conditions to extreme levels that demand immediate attention.
🔶 Momentum Confirmation System
Incorporates a specialized momentum histogram that confirms mean reversion signals by analyzing the rate of change in the composite oscillator. This prevents premature entries during strong trending conditions while highlighting genuine reversal opportunities.
// Oscillator momentum (rate of change)
osc_momentum = ta.mom(composite, 5)
histogram = osc_momentum
// Momentum confirmation
momentum_bullish = histogram > histogram
momentum_bearish = histogram < histogram
// Confirmed signals
confirmed_bullish = bullish_entry and momentum_bullish
confirmed_bearish = bearish_entry and momentum_bearish
🔶 Dynamic Visual Intelligence
The oscillator line adapts its color intensity based on proximity to extreme levels, providing instant visual feedback about market conditions. Background shading creates clear zones that highlight when markets enter moderate or extreme territories.
🔶 Intelligent Signal Generation
Generates precise entry signals only when the composite oscillator crosses extreme thresholds with momentum confirmation. This dual-confirmation approach significantly reduces false signals while maintaining sensitivity to genuine mean reversion opportunities.
How It Works
🔶 Composite Score Calculation
The indicator simultaneously tracks five different oscillators, each normalized to a 0-100 scale, then combines them into a smoothed composite score. This approach eliminates the noise inherent in single-oscillator analysis while capturing the consensus view of multiple momentum indicators.
// Mean reversion entry signals
bullish_entry = ta.crossover(composite, 100 - extreme_level) and composite < (100 - extreme_level)
bearish_entry = ta.crossunder(composite, extreme_level) and composite > extreme_level
// Bollinger %B calculation
bb_basis = ta.sma(src, bb_length)
bb_dev = bb_mult * ta.stdev(src, bb_length)
bb_percent = (src - bb_lower) / (bb_upper - bb_lower) * 100
🔶 Extreme Zone Identification
The system automatically identifies when markets reach statistically significant extreme levels, both moderate (65/35) and extreme (80/20). These zones represent areas where mean reversion has the highest probability of success based on historical market behavior.
🔶 Momentum Histogram Analysis
A specialized momentum histogram tracks the velocity of oscillator changes, helping traders distinguish between healthy corrections and potential trend reversals. The histogram's color-coded display makes momentum shifts immediately apparent.
🔶 Divergence Detection Framework
Built-in divergence analysis identifies situations where price and oscillator movements diverge, often signaling impending reversals. Diamond-shaped markers highlight these critical divergence patterns for enhanced pattern recognition.
🔶 Real-Time Information Dashboard
An integrated information table provides instant access to current oscillator readings, market status, and individual component values. This dashboard eliminates the need to manually check multiple indicators while trading.
🔶 Individual Component Display
Optional display of individual oscillator components allows traders to understand which specific indicators are driving the composite signal. This transparency enables more informed decision-making and deeper market analysis.
🔶 Adaptive Background Coloring
Intelligent background shading automatically adjusts based on market conditions, creating visual zones that correspond to different levels of mean reversion potential. The subtle color gradations make pattern recognition effortless.
1D
3D
🔶 Comprehensive Alert System
Multi-tier alert system covers confirmed entry signals, divergence patterns, and extreme level breaches. Each alert type provides specific context about the detected condition, enabling traders to respond appropriately to different signal strengths.
🔶 Customizable Threshold Management
Fully adjustable extreme and moderate levels allow traders to fine-tune the indicator's sensitivity to match different market volatilities and trading timeframes. This flexibility ensures optimal performance across various market conditions.
🔶 Why Choose AE - Mean Reversion Oscillator?
This indicator provides the most comprehensive approach to mean reversion trading by combining multiple proven oscillators with advanced confirmation mechanisms. By offering clear visual hierarchies for different extreme levels and requiring momentum confirmation for signals, it empowers traders to identify high-probability contrarian opportunities while avoiding false reversals. The sophisticated composite methodology ensures that signals are both statistically significant and practically actionable, making it an essential tool for traders focused on mean reversion strategies across all market conditions.
Historical Matrix Analyzer [PhenLabs]📊Historical Matrix Analyzer
Version: PineScriptv6
📌Description
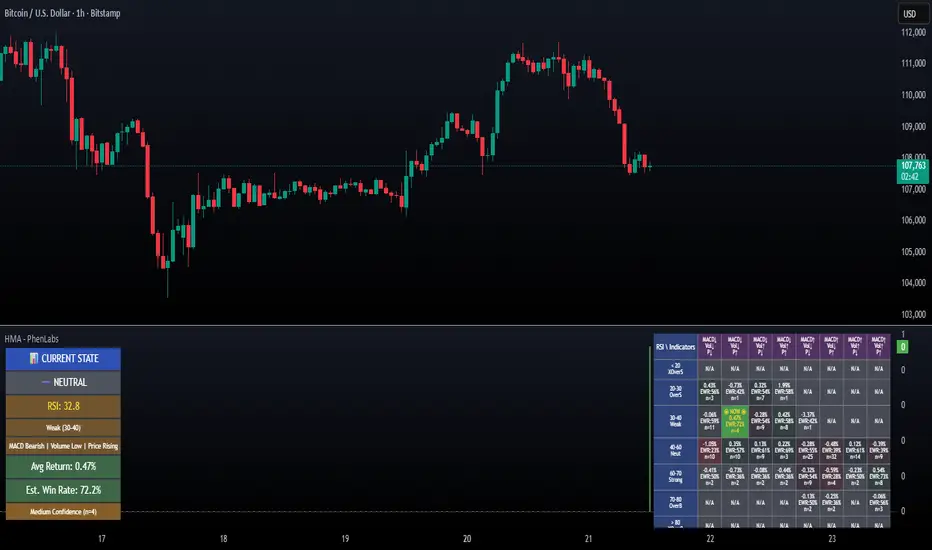
The Historical Matrix Analyzer is an advanced probabilistic trading tool that transforms technical analysis into a data-driven decision support system. By creating a comprehensive 56-cell matrix that tracks every combination of RSI states and multi-indicator conditions, this indicator reveals which market patterns have historically led to profitable outcomes and which have not.
At its core, the indicator continuously monitors seven distinct RSI states (ranging from Extreme Oversold to Extreme Overbought) and eight unique indicator combinations (MACD direction, volume levels, and price momentum). For each of these 56 possible market states, the system calculates average forward returns, win rates, and occurrence counts based on your configurable lookback period. The result is a color-coded probability matrix that shows you exactly where you stand in the historical performance landscape.
The standout feature is the Current State Panel, which provides instant clarity on your active market conditions. This panel displays signal strength classifications (from Strong Bullish to Strong Bearish), the average return percentage for similar past occurrences, an estimated win rate using Bayesian smoothing to prevent small-sample distortions, and a confidence level indicator that warns you when insufficient data exists for reliable conclusions.
🚀Points of Innovation
Multi-dimensional state classification combining 7 RSI levels with 8 indicator combinations for 56 unique trackable market conditions
Bayesian win rate estimation with adjustable smoothing strength to provide stable probability estimates even with limited historical samples
Real-time active cell highlighting with “NOW” marker that visually connects current market conditions to their historical performance data
Configurable color intensity sensitivity allowing traders to adjust heat-map responsiveness from conservative to aggressive visual feedback
Dual-panel display system separating the comprehensive statistics matrix from an easy-to-read current state summary panel
Intelligent confidence scoring that automatically warns traders when occurrence counts fall below reliable thresholds
🔧Core Components
RSI State Classification: Segments RSI readings into 7 distinct zones (Extreme Oversold <20, Oversold 20-30, Weak 30-40, Neutral 40-60, Strong 60-70, Overbought 70-80, Extreme Overbought >80) to capture momentum extremes and transitions
Multi-Indicator Condition Tracking: Simultaneously monitors MACD crossover status (bullish/bearish), volume relative to moving average (high/low), and price direction (rising/falling) creating 8 binary-encoded combinations
Historical Data Storage Arrays: Maintains rolling lookback windows storing RSI states, indicator states, prices, and bar indices for precise forward-return calculations
Forward Performance Calculator: Measures price changes over configurable forward bar periods (1-20 bars) from each historical state, accumulating total returns and win counts per matrix cell
Bayesian Smoothing Engine: Applies statistical prior assumptions (default 50% win rate) weighted by user-defined strength parameter to stabilize estimated win rates when sample sizes are small
Dynamic Color Mapping System: Converts average returns into color-coded heat map with intensity adjusted by sensitivity parameter and transparency modified by confidence levels
🔥Key Features
56-Cell Probability Matrix: Comprehensive grid displaying every possible combination of RSI state and indicator condition, with each cell showing average return percentage, estimated win rate, and occurrence count for complete statistical visibility
Current State Info Panel: Dedicated display showing your exact position in the matrix with signal strength emoji indicators, numerical statistics, and color-coded confidence warnings for immediate situational awareness
Customizable Lookback Period: Adjustable historical window from 50 to 500 bars allowing traders to focus on recent market behavior or capture longer-term pattern stability across different market cycles
Configurable Forward Performance Window: Select target holding periods from 1 to 20 bars ahead to align probability calculations with your trading timeframe, whether day trading or swing trading
Visual Heat Mapping: Color-coded cells transition from red (bearish historical performance) through gray (neutral) to green (bullish performance) with intensity reflecting statistical significance and occurrence frequency
Intelligent Data Filtering: Minimum occurrence threshold (1-10) removes unreliable patterns with insufficient historical samples, displaying gray warning colors for low-confidence cells
Flexible Layout Options: Independent positioning of statistics matrix and info panel to any screen corner, accommodating different chart layouts and personal preferences
Tooltip Details: Hover over any matrix cell to see full RSI label, complete indicator status description, precise average return, estimated win rate, and total occurrence count
🎨Visualization
Statistics Matrix Table: A 9-column by 8-row grid with RSI states labeling vertical axis and indicator combinations on horizontal axis, using compact abbreviations (XOverS, OverB, MACD↑, Vol↓, P↑) for space efficiency
Active Cell Indicator: The current market state cell displays “⦿ NOW ⦿” in yellow text with enhanced color saturation to immediately draw attention to relevant historical performance
Signal Strength Visualization: Info panel uses emoji indicators (🔥 Strong Bullish, ✅ Bullish, ↗️ Weak Bullish, ➖ Neutral, ↘️ Weak Bearish, ⛔ Bearish, ❄️ Strong Bearish, ⚠️ Insufficient Data) for rapid interpretation
Histogram Plot: Below the price chart, a green/red histogram displays the current cell’s average return percentage, providing a time-series view of how historical performance changes as market conditions evolve
Color Intensity Scaling: Cell background transparency and saturation dynamically adjust based on both the magnitude of average returns and the occurrence count, ensuring visual emphasis on reliable patterns
Confidence Level Display: Info panel bottom row shows “High Confidence” (green), “Medium Confidence” (orange), or “Low Confidence” (red) based on occurrence counts relative to minimum threshold multipliers
📖Usage Guidelines
RSI Period
Default: 14
Range: 1 to unlimited
Description: Controls the lookback period for RSI momentum calculation. Standard 14-period provides widely-recognized overbought/oversold levels. Decrease for faster, more sensitive RSI reactions suitable for scalping. Increase (21, 28) for smoother, longer-term momentum assessment in swing trading. Changes affect how quickly the indicator moves between the 7 RSI state classifications.
MACD Fast Length
Default: 12
Range: 1 to unlimited
Description: Sets the faster exponential moving average for MACD calculation. Standard 12-period setting works well for daily charts and captures short-term momentum shifts. Decreasing creates more responsive MACD crossovers but increases false signals. Increasing smooths out noise but delays signal generation, affecting the bullish/bearish indicator state classification.
MACD Slow Length
Default: 26
Range: 1 to unlimited
Description: Defines the slower exponential moving average for MACD calculation. Traditional 26-period setting balances trend identification with responsiveness. Must be greater than Fast Length. Wider spread between fast and slow increases MACD sensitivity to trend changes, impacting the frequency of indicator state transitions in the matrix.
MACD Signal Length
Default: 9
Range: 1 to unlimited
Description: Smoothing period for the MACD signal line that triggers bullish/bearish state changes. Standard 9-period provides reliable crossover signals. Shorter values create more frequent state changes and earlier signals but with more whipsaws. Longer values produce more confirmed, stable signals but with increased lag in detecting momentum shifts.
Volume MA Period
Default: 20
Range: 1 to unlimited
Description: Lookback period for volume moving average used to classify volume as “high” or “low” in indicator state combinations. 20-period default captures typical monthly trading patterns. Shorter periods (10-15) make volume classification more reactive to recent spikes. Longer periods (30-50) require more sustained volume changes to trigger state classification shifts.
Statistics Lookback Period
Default: 200
Range: 50 to 500
Description: Number of historical bars used to calculate matrix statistics. 200 bars provides substantial data for reliable patterns while remaining responsive to regime changes. Lower values (50-100) emphasize recent market behavior and adapt quickly but may produce volatile statistics. Higher values (300-500) capture long-term patterns with stable statistics but slower adaptation to changing market dynamics.
Forward Performance Bars
Default: 5
Range: 1 to 20
Description: Number of bars ahead used to calculate forward returns from each historical state occurrence. 5-bar default suits intraday to short-term swing trading (5 hours on hourly charts, 1 week on daily charts). Lower values (1-3) target short-term momentum trades. Higher values (10-20) align with position trading and longer-term pattern exploitation.
Color Intensity Sensitivity
Default: 2.0
Range: 0.5 to 5.0, step 0.5
Description: Amplifies or dampens the color intensity response to average return magnitudes in the matrix heat map. 2.0 default provides balanced visual emphasis. Lower values (0.5-1.0) create subtle coloring requiring larger returns for full saturation, useful for volatile instruments. Higher values (3.0-5.0) produce vivid colors from smaller returns, highlighting subtle edges in range-bound markets.
Minimum Occurrences for Coloring
Default: 3
Range: 1 to 10
Description: Required minimum sample size before applying color-coded performance to matrix cells. Cells with fewer occurrences display gray “insufficient data” warning. 3-occurrence default filters out rare patterns. Lower threshold (1-2) shows more data but includes unreliable single-event statistics. Higher thresholds (5-10) ensure only well-established patterns receive visual emphasis.
Table Position
Default: top_right
Options: top_left, top_right, bottom_left, bottom_right
Description: Screen location for the 56-cell statistics matrix table. Position to avoid overlapping critical price action or other indicators on your chart. Consider chart orientation and candlestick density when selecting optimal placement.
Show Current State Panel
Default: true
Options: true, false
Description: Toggle visibility of the dedicated current state information panel. When enabled, displays signal strength, RSI value, indicator status, average return, estimated win rate, and confidence level for active market conditions. Disable to declutter charts when only the matrix table is needed.
Info Panel Position
Default: bottom_left
Options: top_left, top_right, bottom_left, bottom_right
Description: Screen location for the current state information panel (when enabled). Position independently from statistics matrix to optimize chart real estate. Typically placed opposite the matrix table for balanced visual layout.
Win Rate Smoothing Strength
Default: 5
Range: 1 to 20
Description: Controls Bayesian prior weighting for estimated win rate calculations. Acts as virtual sample size assuming 50% win rate baseline. Default 5 provides moderate smoothing preventing extreme win rate estimates from small samples. Lower values (1-3) reduce smoothing effect, allowing win rates to reflect raw data more directly. Higher values (10-20) increase conservatism, pulling win rate estimates toward 50% until substantial evidence accumulates.
✅Best Use Cases
Pattern-based discretionary trading where you want historical confirmation before entering setups that “look good” based on current technical alignment
Swing trading with holding periods matching your forward performance bar setting, using high-confidence bullish cells as entry filters
Risk assessment and position sizing, allocating larger size to trades originating from cells with strong positive average returns and high estimated win rates
Market regime identification by observing which RSI states and indicator combinations are currently producing the most reliable historical patterns
Backtesting validation by comparing your manual strategy signals against the historical performance of the corresponding matrix cells
Educational tool for developing intuition about which technical condition combinations have actually worked versus those that feel right but lack historical evidence
⚠️Limitations
Historical patterns do not guarantee future performance, especially during unprecedented market events or regime changes not represented in the lookback period
Small sample sizes (low occurrence counts) produce unreliable statistics despite Bayesian smoothing, requiring caution when acting on low-confidence cells
Matrix statistics lag behind rapidly changing market conditions, as the lookback period must accumulate new state occurrences before updating performance data
Forward return calculations use fixed bar periods that may not align with actual trade exit timing, support/resistance levels, or volatility-adjusted profit targets
💡What Makes This Unique
Multi-Dimensional State Space: Unlike single-indicator tools, simultaneously tracks 56 distinct market condition combinations providing granular pattern resolution unavailable in traditional technical analysis
Bayesian Statistical Rigor: Implements proper probabilistic smoothing to prevent overconfidence from limited data, a critical feature missing from most pattern recognition tools
Real-Time Contextual Feedback: The “NOW” marker and dedicated info panel instantly connect current market conditions to their historical performance profile, eliminating guesswork
Transparent Occurrence Counts: Displays sample sizes directly in each cell, allowing traders to judge statistical reliability themselves rather than hiding data quality issues
Fully Customizable Analysis Window: Complete control over lookback depth and forward return horizons lets traders align the tool precisely with their trading timeframe and strategy requirements
🔬How It Works
1. State Classification and Encoding
Each bar’s RSI value is evaluated and assigned to one of 7 discrete states based on threshold levels (0: <20, 1: 20-30, 2: 30-40, 3: 40-60, 4: 60-70, 5: 70-80, 6: >80)
Simultaneously, three binary conditions are evaluated: MACD line position relative to signal line, current volume relative to its moving average, and current close relative to previous close
These three binary conditions are combined into a single indicator state integer (0-7) using binary encoding, creating 8 possible indicator combinations
The RSI state and indicator state are stored together, defining one of 56 possible market condition cells in the matrix
2. Historical Data Accumulation
As each bar completes, the current state classification, closing price, and bar index are stored in rolling arrays maintained at the size specified by the lookback period
When the arrays reach capacity, the oldest data point is removed and the newest added, creating a sliding historical window
This continuous process builds a comprehensive database of past market conditions and their subsequent price movements
3. Forward Return Calculation and Statistics Update
On each bar, the indicator looks back through the stored historical data to find bars where sufficient forward bars exist to measure outcomes
For each historical occurrence, the price change from that bar to the bar N periods ahead (where N is the forward performance bars setting) is calculated as a percentage return
This percentage return is added to the cumulative return total for the specific matrix cell corresponding to that historical bar’s state classification
Occurrence counts are incremented, and wins are tallied for positive returns, building comprehensive statistics for each of the 56 cells
The Bayesian smoothing formula combines these raw statistics with prior assumptions (neutral 50% win rate) weighted by the smoothing strength parameter to produce estimated win rates that remain stable even with small samples
💡Note:
The Historical Matrix Analyzer is designed as a decision support tool, not a standalone trading system. Best results come from using it to validate discretionary trade ideas or filter systematic strategy signals. Always combine matrix insights with proper risk management, position sizing rules, and awareness of broader market context. The estimated win rate feature uses Bayesian statistics specifically to prevent false confidence from limited data, but no amount of smoothing can create reliable predictions from fundamentally insufficient sample sizes. Focus on high-confidence cells (green-colored confidence indicators) with occurrence counts well above your minimum threshold for the most actionable insights.
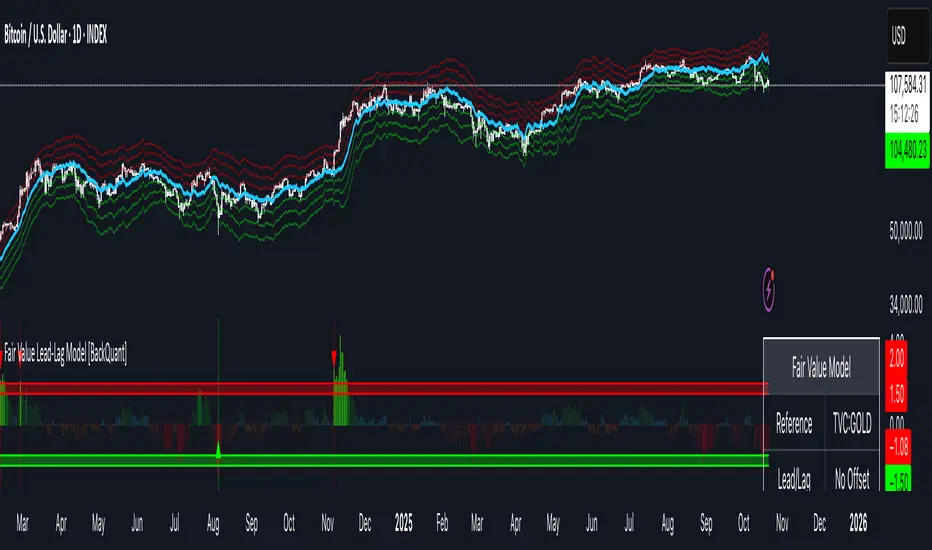
Fair Value Lead-Lag Model [BackQuant]Fair Value Lead-Lag Model
A cross-asset model that estimates where price "should" be relative to a chosen reference series, then tracks the deviation as a normalized oscillator. It helps you answer two questions: 1) is the asset rich or cheap vs its driver, and 2) is the driver leading or lagging price over the next N bars.
Concept in one paragraph
Many assets co-move with a macro or sector driver. Think BTC vs DXY, gold vs real yields, a stock vs its sector ETF. This tool builds a rolling fair value of the charted asset from a reference series and shows how far price is above or below that fair value in standard deviation units. You can shift the reference forward or backward to test who leads whom, then use the deviation and its bands to structure mean-reversion or trend-following ideas.
What the model does
Reference mapping : Pulls a reference symbol at a chosen timeframe, with an optional lead or lag in bars to test causality.
Fair value engine : Converts the reference into a synthetic fair value of the chart using one of four methods:
Ratio : price/ref with a rolling average ratio. Good when the relationship is proportional.
Spread : price minus ref with a rolling average spread. Good when the relationship is additive.
Z-Score : normalizes both series, aligns on standardized units, then re-projects to price space. Good when scale drifts.
Beta-Adjusted : rolling regression style. Uses covariance and variance to compute beta, then builds a fair value = mean(price) + beta * (ref − mean(ref)).
Deviation and bands : Computes a z-scored deviation of price vs fair value and plots sigma bands (±1, ±2, ±3) around the fair value line on the chart.
Correlation context : Shows rolling correlation so you can judge if deviations are meaningful or just noise when co-movement is weak.
Visuals :
Fair value line on price chart with sigma envelopes.
Deviation as a column oscillator and optional line.
Threshold shading beyond user-set upper and lower levels.
Summary table with reference, deviation, status, correlation, and method.
Why this is useful
Mean reversion framework : When correlation is healthy and deviation stretches beyond your sigma threshold, probability favors reversion toward fair value. This is classic pairs logic adapted to a driver and a target.
Trend confirmation : If price rides the fair value line and deviation stays modest while correlation is positive, it supports trend persistence. Pullbacks to negative deviation in an uptrend can be buyable.
Lead-lag discovery : Shift the reference forward by +N bars. If correlation improves, the reference tends to lead. Shift backward for the reverse. Use the best setting for planning early entries or hedges.
Regime detection : Large persistent deviations with falling correlation hint at regime change. The relationship you relied on may be breaking down, so reduce confidence or switch methods.
How to use it step by step
Pick a sensible reference : Choose a macro, index, currency, or sector driver that logically explains the asset’s moves. Example: gold with DXY, a semiconductor stock with SOXX.
Test lead-lag : Nudge Lead/Lag Periods to small positive values like +1 to +5 to see if the reference leads. If correlation improves, keep that offset. If correlation worsens, try a small negative value or zero.
Select a method :
Start with Beta-Adjusted when the relationship is approximately linear with drift.
Use Ratio if the assets usually move in proportional terms.
Use Spread when they trade around a level difference.
Use Z-Score when scales wander or volatility regimes shift.
Tune windows :
Rolling Window controls how quickly fair value adapts. Shorter equals faster but noisier.
Normalization Period controls how deviations are standardized. Longer equals stabler sigma sizing.
Correlation Length controls how co-movement is measured. Keep it near the fair value window.
Trade the edges :
Mean reversion idea : Wait for deviation beyond your Upper or Lower Threshold with positive correlation. Fade back toward fair value. Exit at the fair value line or the next inner sigma band.
Trend idea : In an uptrend, buy pullbacks when deviation dips negative but correlation remains healthy. In a downtrend, sell bounces when deviation spikes positive.
Read the table : Deviation shows how many sigmas you are from fair value. Status tells you overvalued or undervalued. Correlation color hints confidence. Method tells you the projection style used.
Reading the display
Fair value line on price chart: the model’s estimate of where price should trade given the reference, updated each bar.
Sigma bands around fair value: a quick sense of residual volatility. Reversions often target inner bands first.
Deviation oscillator : above zero means rich vs fair value, below zero means cheap. Color bins intensify with distance.
Correlation line (optional): scale is folded to match thresholds. Higher values increase trust in deviations.
Parameter tips
Start with Rolling Window 20 to 30, Normalization Period 100, Correlation Length 50.
Upper and Lower Threshold at ±2.0 are classic. Tighten to ±1.5 for more signals or widen to ±2.5 to focus on outliers.
When correlation drifts below about 0.3, treat deviations with caution. Consider switching method or reference.
If the fair value line whipsaws, increase Rolling Window or move to Beta-Adjusted which tends to be smoother.
Playbook examples
Pairs-style reversion : Asset is +2.3 sigma rich vs reference, correlation 0.65, trend flat. Short the deviation back toward fair value. Cover near the fair value line or +1 sigma.
Pro-trend pullback : Uptrend with correlation 0.7. Deviation dips to −1.2 sigma while price sits near the −1 sigma band. Buy the dip, target the fair value line, trail if the line is rising.
Lead-lag timing : Reference leads by +3 bars with improved correlation. Use reference swings as early cues to anticipate deviation turns on the target.
Caveats
The model assumes a stable relationship over the chosen windows. Structural breaks, policy shocks, and index rebalances can invalidate recent history.
Correlation is descriptive, not causal. A strong correlation does not guarantee future convergence.
Do not force trades when the reference has low liquidity or mismatched hours. Use a reference timeframe that captures real overlap.
Bottom line
This tool turns a loose cross-asset intuition into a quantified, visual fair value map. It gives you a consistent way to find rich or cheap conditions, time mean-reversion toward a statistically grounded target, and confirm or fade trends when the driver agrees.
Relative Performance Tracker [QuantAlgo]🟢 Overview
The Relative Performance Tracker is a multi-asset comparison tool designed to monitor and rank up to 30 different tickers simultaneously based on their relative price performance. This indicator enables traders and investors to quickly identify market leaders and laggards across their watchlist, facilitating rotation strategies, strength-based trading decisions, and cross-asset momentum analysis.
🟢 Key Features
1. Multi-Asset Monitoring
Track up to 30 tickers across any market (stocks, crypto, forex, commodities, indices)
Individual enable/disable toggles for each ticker to customize your watchlist
Universal compatibility with any TradingView symbol format (EXCHANGE:TICKER)
2. Ranking Tables (Up to 3 Tables)
Each ticker's percentage change over your chosen lookback period, calculated as:
(Current Price - Past Price) / Past Price × 100
Automatic sorting from strongest to weakest performers
Rank: Position from 1-30 (1 = strongest performer)
Ticker: Symbol name with color-coded background (green for gains, red for losses)
% Change: Exact percentage with color intensity matching magnitude
For example, Rank #1 has the highest gain among all enabled tickers, Rank #30 has the lowest (or most negative) return.
3. Histogram Visualization
Adjustable bar count: Display anywhere from 1 to 30 top-ranked tickers (user customizable)
Bar height = magnitude of percentage change.
Bars extend upward for gains, downward for losses. Taller bars = larger moves.
Green bars for positive returns, red for negative returns.
4. Customizable Color Schemes
Classic: Traditional green/red for intuitive interpretation
Aqua: Blue/orange combination for reduced eye strain
Cosmic: Vibrant aqua/purple optimized for dark mode
Custom: Full personalization of positive and negative colors
5. Built-In Ranking Alerts
Six alert conditions detect when rankings change:
Top 1 Changed: New #1 leader emerges
Top 3/5/10/15/20 Changed: Shifts within those tiers
🟢 Practical Applications
→ Momentum Trading: Focus on top-ranked assets (Rank 1-10) that show strongest relative strength for trend-following strategies
→ Market Breadth Analysis: Monitor how many tickers are above vs. below zero on the histogram to gauge overall market health
→ Divergence Spotting: Identify when previously leading assets lose momentum (drop out of top ranks) as potential trend reversal signals
→ Multi-Timeframe Analysis: Use different lookback periods on different charts to align short-term and long-term relative strength
→ Customized Focus: Adjust histogram bars to show only top 5-10 strongest movers for concentrated analysis, or expand to 20-30 for comprehensive overview

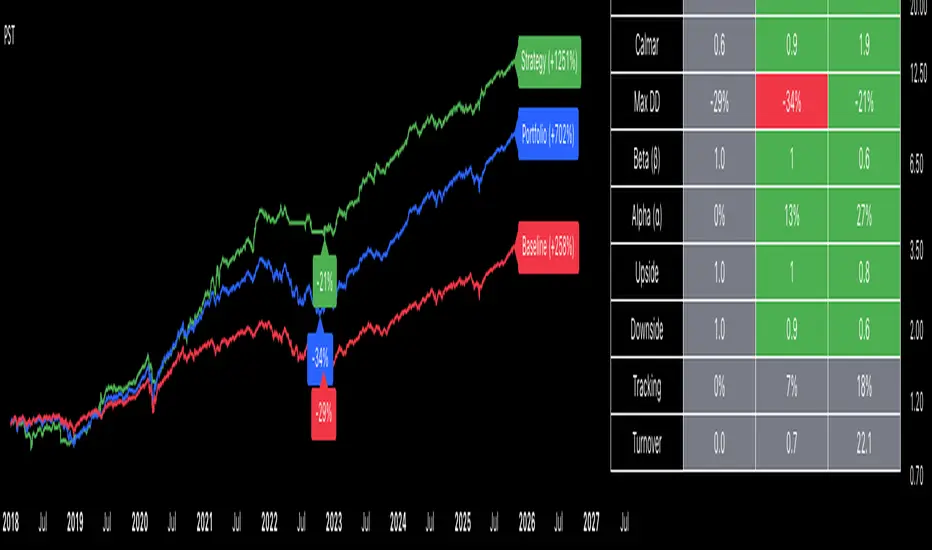
Portfolio Strategy TesterThe Portfolio Strategy Tester is an institutional-grade backtesting framework that evaluates the performance of trend-following strategies on multi-asset portfolios. It enables users to construct custom portfolios of up to 30 assets and apply moving average crossover strategies across individual holdings. The model features a clear, color-coded table that provides a side-by-side comparison between the buy-and-hold portfolio and the portfolio using the risk management strategy, offering a comprehensive assessment of both approaches relative to the benchmark.
Portfolios are constructed by entering each ticker symbol in the menu, assigning its respective weight, and reviewing the total sum of individual weights displayed at the top left of the table. For strategy selection, users can choose between Exponential Moving Average (EMA), Simple Moving Average (SMA), Wilder’s Moving Average (RMA), Weighted Moving Average (WMA), Moving Average Convergence Divergence (MACD), and Volume-Weighted Moving Average (VWMA). Moving average lengths are defined in the menu and apply only to strategy-enabled assets.
To accurately replicate real-world portfolio conditions, users can choose between daily, weekly, monthly, or quarterly rebalancing frequencies and decide whether cash is held or redistributed. Daily rebalancing maintains constant portfolio weights, while longer intervals allow natural drift. When cash positions are not allowed, capital from bearish assets is automatically redistributed proportionally among bullish assets, ensuring the portfolio remains fully invested at all times. The table displays a comprehensive set of widely used institutional-grade performance metrics:
CAGR = Compounded annual growth rate of returns.
Volatility = Annualized standard deviation of returns.
Sharpe = CAGR per unit of annualized standard deviation.
Sortino = CAGR per unit of annualized downside deviation.
Calmar = CAGR relative to maximum drawdown.
Max DD = Largest peak-to-trough decline in value.
Beta (β) = Sensitivity of returns relative to benchmark returns.
Alpha (α) = Excess annualized risk-adjusted returns relative to benchmark.
Upside = Ratio of average return to benchmark return on up days.
Downside = Ratio of average return to benchmark return on down days.
Tracking = Annualized standard deviation of returns versus benchmark.
Turnover = Average sum of absolute changes in weights per year.
Cumulative returns are displayed on each label as the total percentage gain from the selected start date, with green indicating positive returns and red indicating negative returns. In the table, baseline metrics serve as the benchmark reference and are always gray. For portfolio metrics, green indicates outperformance relative to the baseline, while red indicates underperformance relative to the baseline. For strategy metrics, green indicates outperformance relative to both the baseline and the portfolio, red indicates underperformance relative to both, and gray indicates underperformance relative to either the baseline or portfolio. Metrics such as Volatility, Tracking Error, and Turnover ratio are always displayed in gray as they serve as descriptive measures.
In summary, the Portfolio Strategy Tester is a comprehensive backtesting tool designed to help investors evaluate different trend-following strategies on custom portfolios. It enables real-world simulation of both active and passive investment approaches and provides a full set of standard institutional-grade performance metrics to support data-driven comparisons. While results are based on historical performance, the model serves as a powerful portfolio management and research framework for developing, validating, and refining systematic investment strategies.
Volume Profile, Pivot Anchored by DGT - reviewedVolume Profile, Pivot Anchored by DGT - reviewed
This indicator, “Volume Profile, Pivot Anchored”, builds a volume profile between swing highs and lows (pivot points) to show where trading activity is concentrated.
It highlights:
Value Area (VAH / VAL) and Point of Control (POC)
Volume distribution by price level
Pivot-based labels showing price, % change, and volume
Optional colored candles based on volume strength relative to the average
Essentially, it visualizes how volume is distributed between market pivots to reveal key price zones and volume imbalances.
Master Trend Strategy - by jake_thebossMaster Trend Strategy
This strategy combines multiple technical indicators to identify high-probability trend entries across all asset classes.
Core Signal Logic:
Entry triggered when EMA 4 crosses above/below EMA 5
Confirmation required from RSI (>50 for long, <50 for short)
Price must be above/below key moving averages: EMA 21, SMA 50, EMA 55, EMA 89, and EMA 750
Additional confirmation from Stochastic (>52 bullish, <48 bearish) or EMA 89 breakout or VWAP cross
Key Features:
VWAP filter: Only takes bullish signals above VWAP and bearish signals below VWAP
Optional pyramiding: Allows multiple entries in the same direction (up to 200 orders)
Individual stop loss and take profit management for each pyramid level
Time filter: Customizable trading hours with timezone offset
Risk management: Adjustable stop loss (default 0.3%) and take profit (default 0.6%)
Visualization:
Entry, stop loss, and take profit levels drawn as horizontal lines
Customizable signal markers (triangles) for bull/bear entries
Optional EMA overlay display
The strategy is designed for trend-following on lower timeframes, with strict multi-indicator confirmation to filter out false signals.

NY Session Range Box with Labeled Time MarkersShows opening time ny session by timing with lines to inform traders to avoid 11:30am to 1:30pm for choppy sessions and mark early and power hour .

Scalping m15 indicator RovTradingScalping Indicator Combining UT Bot and Linear Regression Candles.
UT Bot uses ATR Trailing Stop to identify entry points.
Linear Regression Candles smooth price action and provide trend signals.
The indicator is suitable for scalping trading on the M15 timeframe.

UTBotLibrary "UTBot"
is a powerful and flexible trading toolkit implemented in Pine Script. Based on the widely recognized UT Bot strategy originally developed by Yo_adriiiiaan with important enhancements by HPotter, this library provides users with customizable functions for dynamic trailing stop calculations using ATR (Average True Range), trend detection, and signal generation. It enables developers and traders to seamlessly integrate UT Bot logic into their own indicators and strategies without duplicating code.
Key features include:
Accurate ATR-based trailing stop and reversal detection
Multi-timeframe support for enhanced signal reliability
Clean and efficient API for easy integration and customization
Detailed documentation and examples for quick adoption
Open-source and community-friendly, encouraging collaboration and improvements
We sincerely thank Yo_adriiiiaan for the original UT Bot concept and HPotter for valuable improvements that have made this strategy even more robust. This library aims to honor their work by making the UT Bot methodology accessible to Pine Script developers worldwide.
This library is designed for Pine Script programmers looking to leverage the proven UT Bot methodology to build robust trading systems with minimal effort and maximum maintainability.
UTBot(h, l, c, multi, leng)
Parameters:
h (float) - high
l (float) - low
c (float)-close
multi (float)- multi for ATR
leng (int)-length for ATR
Returns:
xATRTS - ATR Based TrailingStop Value
pos - pos==1, long position, pos==-1, shot position
signal - 0 no signal, 1 buy, -1 sell

Nq/ES daily CME risk intervalReverse engineering the risk interval for CME (Chicago Mercantile Exchange) products based on margin requirements involves understanding the relationship between margin requirements, volatility, and the risk interval (price movement assumed for margin calculation)
The CME uses a methodology called SPAN (Standard Portfolio Analysis of Risk) to calculate margins. At a high level, the initial margin is derived from:
Initial Margin = Risk Interval × Contract Size × Volatility Adjustment Factor
Where:
Risk Interval: The price movement range used in the margin calculation.
Contract Size: The unit size of the futures contract.
Volatility Adjustment Factor: A measure of how much price fluctuation is expected, often tied to historical volatility.
To calculate an approximate of the daily CME risk interval, we need:
Initial Margin Requirement: Available on the CME Group website or broker platforms.
Contract Size: The size of one futures contract (e.g., for the S&P 500 E-mini, it is $50 × index points).
Volatility Adjustment Factor: This is derived from historical volatility or CME's implied volatility estimates.
As we do not have access to CME calculations , the volatility adjustment factor can be estimated using historical volatility: We calculate the standard deviation of daily returns over a specific period (e.g., 20 or 30 or 60 days).
Key Considerations
The exact formulas and parameters used by CME for CME's implied volatility estimates are proprietary, so this calculation based on standard deviation of daily returns is an approximation.
How to use:
Input the maintenance margin obtained from the CME website.
Adjust volatility period calculation.
The indicator displays the range high and low for the trading day.
1.Lines can be used as targets intraday
2.Market tends to snap back in between the lines and close the day in the range

Live Volume TickerGives current real-time volume of tick movements denoted in the timeframe of the current candle.

PPI Inflation Monitor (Change YoY & MoM)📊 PPI Inflation Monitor - Leading Inflation Indicator
The Producer Price Index (PPI) measures wholesale/producer-level prices and serves as a critical leading indicator for consumer inflation trends. This tool helps you anticipate CPI movements and identify corporate margin pressures before they show up in earnings.
🎯 KEY FEATURES:
- Dual Perspective Analysis:
- Year-over-Year (YoY): Histogram bars showing annual producer price inflation
- Month-over-Month (MoM): Line overlay showing monthly wholesale price changes
- Visual Reference System:
- Dashed line at 2% (typical target for producer price inflation)
- Dotted line at 0.17% (equivalent monthly target)
- Color-coded bars: Red above target, Green below target
- Real-Time Data Table:
- Current PPI Index value
- YoY inflation rate with color coding
- MoM inflation rate with color coding
- Deviation from target level
- Automated Alerts:
- YoY crosses above/below target
- MoM crosses above/below target
- Early warning system for inflation trends
📈 WHY PPI IS YOUR EARLY WARNING SYSTEM:
PPI typically leads CPI by 1-3 months because:
- Producers face cost increases first
- These costs are eventually passed to consumers
- Shows whether companies can maintain pricing power
Rising PPI with stable CPI = Margin compression → Bearish for stocks
Rising PPI followed by rising CPI = Broad inflation → Fed hawkishness incoming
Falling PPI = Disinflationary trend starting → Positive for risk assets
🔍 TRADING APPLICATIONS:
1. Lead Time Advantage: Position before CPI confirms PPI trends
2. Sector Rotation: High PPI = favor companies with pricing power
3. Margin Analysis: PPI-CPI divergence = margin pressure/expansion signals
4. Fed Anticipation: PPI acceleration = Fed likely to turn hawkish soon
💡 STRATEGIC USE CASES:
- Value vs. Growth: Rising PPI favors value stocks with pricing power
- Commodities: PPI often correlates with commodity price trends
- Small Caps: More vulnerable to input cost increases (high PPI = cautious)
- Corporate Earnings: Anticipate margin pressure before quarterly reports
🔄 COMBINE WITH:
- CPI: Confirm if producer costs reach consumers
- PCE: Validate Fed's preferred inflation metric response
- Fed Funds Rate: Assess if Fed is behind/ahead of curve
📊 DATA SOURCE:
Official PPI data from FRED (Federal Reserve Economic Data), updated monthly when new data releases occur.
🎨 CUSTOMIZATION:
Fully customizable:
- Toggle YoY/MoM displays
- Adjust reference target levels
- Customize colors
- Show/hide absolute PPI values
Perfect for: Macro traders, fundamental analysts, earnings traders, and investors seeking early inflation signals before they appear in consumer prices.
⚡ Remember: PPI leads CPI. Use this advantage to position ahead of the crowd.

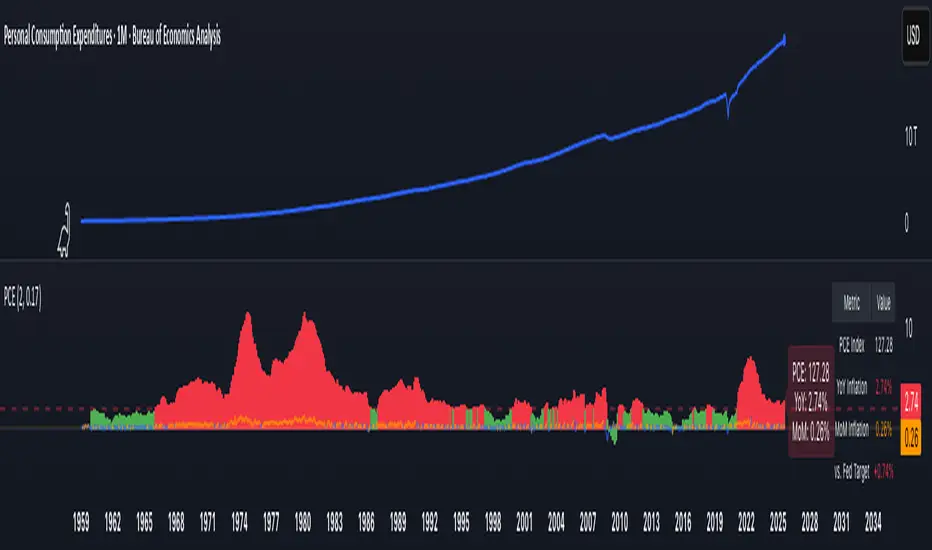
PCE Inflation Monitor (Change YoY & MoM)📊 PCE Inflation Monitor - The Fed's Most Important Metric
Personal Consumption Expenditures (PCE) is the Federal Reserve's preferred inflation measure and THE metric they target for their 2% inflation goal. If you want to predict Fed policy, you need to watch PCE.
🎯 KEY FEATURES:
- Dual Perspective Analysis:
- Year-over-Year (YoY): Histogram bars showing annual PCE inflation
- Month-over-Month (MoM): Line overlay showing monthly consumption price changes
- Visual Reference System:
- Dashed line at 2% (Fed's official PCE inflation target)
- Dotted line at 0.17% (equivalent monthly target)
- Color-coded bars: Red above Fed target, Green below target
- Real-Time Data Table:
- Current PCE Index value
- YoY inflation rate vs. Fed's 2% target
- MoM inflation rate with color coding
- Exact deviation from Fed target (critical for policy predictions)
- Automated Alerts:
- PCE crosses Fed's 2% target (major policy signal!)
- MoM crosses monthly target
- Stay informed of Fed-relevant inflation changes
📈 WHY PCE IS DIFFERENT (AND MORE IMPORTANT):
PCE vs. CPI differences:
- Flexible basket: PCE adjusts for substitution (beef → chicken if prices rise)
- Broader coverage: Includes healthcare paid by insurance/government
- Lower readings: Typically 0.2-0.4% below CPI
- Fed's choice: Explicitly stated as their target metric
Most importantly: When Powell speaks about "our 2% target," he means PCE, not CPI!
🔍 TRADING IMPLICATIONS:
PCE Above 2% (Red Zone):
→ Fed under pressure to maintain/raise rates
→ Hawkish policy stance likely
→ Negative for growth stocks, crypto
→ Positive for USD, bearish for gold
PCE Below 2% (Green Zone):
→ Fed has flexibility to cut rates
→ Dovish policy stance possible
→ Positive for risk assets, growth stocks
→ Negative for USD, bullish for commodities
PCE Approaching 2% from Above:
→ Fed "mission accomplished" narrative
→ Rate cut cycle becomes possible
→ Major bullish signal for equities/crypto
💡 ADVANCED STRATEGIES:
1. Fed Meeting Preparation: Check PCE before FOMC meetings for policy clues
2. Dot Plot Predictions: PCE trend determines Fed's rate forecast updates
3. Pivot Timing: When PCE MoM turns negative, Fed pivot becomes realistic
4. Press Conference Analysis: Compare Powell's comments to PCE deviation
🎯 KEY LEVELS TO WATCH:
- 2.0% YoY: Fed's official target - crossing this level is major news
- 2.5% YoY: "Uncomfortably high" - Fed forced to stay restrictive
- 3.0% YoY: "Crisis mode" - Fed turns very hawkish
- 1.5% YoY: "Below target" - Rate cuts become likely
🔄 COMBINE WITH:
- CPI: Public perception vs. Fed's metric (often diverge)
- Core PCE: Even more important (excludes food/energy volatility)
- Fed Funds Rate: Is Fed responding appropriately to PCE?
📊 DATA SOURCE:
Official PCE data from FRED (Federal Reserve Economic Data), updated monthly typically in the last week of each month (after CPI/PPI releases).
🎨 CUSTOMIZATION:
Fully customizable:
- Toggle YoY/MoM displays
- Adjust Fed target if needed
- Customize colors
- Show/hide absolute PCE values
Perfect for: Fed watchers, macro traders, policy analysts, and serious investors who want to predict monetary policy changes before they happen.
⚠️ CRITICAL INSIGHT: While media focuses on CPI, the Fed focuses on PCE. Trade what the Fed trades, not what the headlines say.
🎓 Pro Tip: Fed members often mention "Core PCE" (excluding food/energy). Consider adding that indicator alongside this one for complete Fed policy analysis.
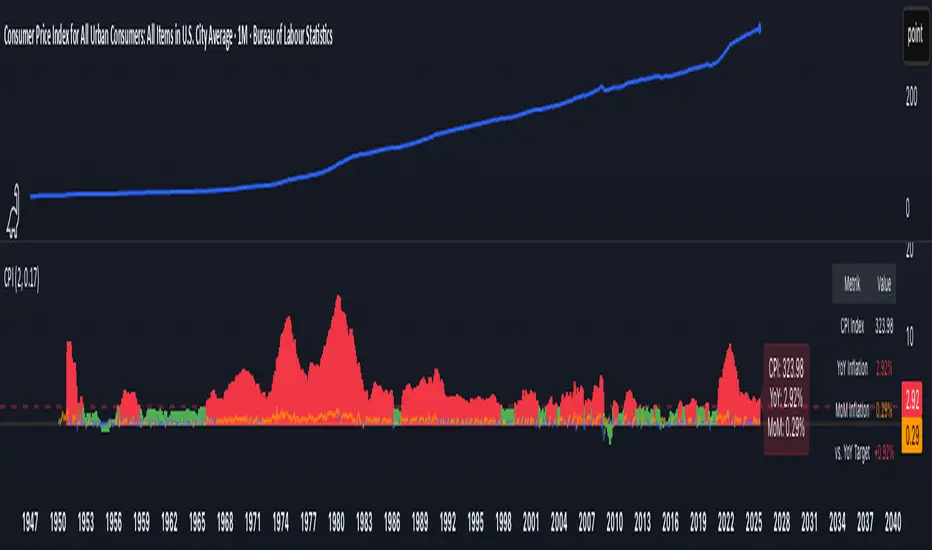
CPI Inflation Monitor (Change YoY & MoM)📊 CPI Inflation Monitor - Complete Macro Analysis Tool
This indicator provides a comprehensive view of Consumer Price Index (CPI) inflation trends, essential for understanding monetary policy, market conditions, and making informed trading decisions.
🎯 KEY FEATURES:
- Dual Perspective Analysis:
- Year-over-Year (YoY): Histogram bars showing annual inflation rate
- Month-over-Month (MoM): Line overlay showing monthly price changes
- Visual Reference System:
- Dashed line at 2% (Fed's official inflation target for YoY)
- Dotted line at 0.17% (equivalent monthly target for MoM)
- Color-coded bars: Red above target, Green below target
- Real-Time Data Table:
- Current CPI Index value
- YoY inflation rate with color coding
- MoM inflation rate with color coding
- Deviation from Fed target
- Automated Alerts:
- YoY crosses above/below 2% target
- MoM crosses above/below 0.17% target
- Perfect for staying informed without constant monitoring
📈 WHY THIS MATTERS FOR TRADERS:
CPI is the most widely reported inflation metric and directly influences:
- Federal Reserve interest rate decisions
- Bond yields and currency valuations
- Stock market sentiment (especially growth vs. value rotation)
- Cryptocurrency and risk asset performance
Rising inflation (red bars) typically leads to:
→ Higher interest rates → Negative for growth stocks, crypto
→ Stronger USD → Pressure on commodities
Falling inflation (green bars) typically leads to:
→ Rate cut expectations → Positive for growth stocks, crypto
→ Weaker USD → Support for commodities
🔍 HOW TO USE:
1. Strategic Positioning: Use YoY trend (thick bars) for long-term asset allocation
2. Tactical Timing: Use MoM trend (thin line) to identify turning points early
3. Divergence Trading: When MoM falls but YoY remains high, anticipate trend reversal
4. Fed Policy Prediction: Distance from 2% target indicates Fed's likely hawkishness
💡 PRO TIPS:
- Multiple months of MoM above 0.3% = Accelerating inflation → Fed turns hawkish
- MoM turning negative while YoY still elevated = Peak inflation → Position for pivot
- Compare with PPI and PCE indicators for complete inflation picture
- Use alerts to catch important threshold crossings automatically
📊 DATA SOURCE:
Official CPI data from FRED (Federal Reserve Economic Data), updated monthly mid-month when new data releases occur.
🎨 CUSTOMIZATION:
Fully customizable through settings:
- Toggle YoY/MoM displays
- Adjust target levels
- Customize colors for visual preference
- Show/hide absolute CPI values
Perfect for: Macro traders, swing traders, long-term investors, and anyone wanting to understand the inflation environment affecting their portfolio.
Note: This indicator works on any chart timeframe as it loads external monthly economic data.
CMF, RSI, CCI, MACD, OBV, Fisher, Stoch RSI, ADX (+DI/-DI)Eight normalized indicators are used in conjunction with the CMF, CCI, MACD, and Stoch RSI indicators. You can track buy and sell decisions by tracking swings. The zero line is for reversal tracking at -20, +20, +50, and +80. You can use any of the nine indicators individually or in combination.


Simplified Percentile ClusteringSimplified Percentile Clustering (SPC) is a clustering system for trend regime analysis.
Instead of relying on heavy iterative algorithms such as k-means, SPC takes a deterministic approach: it uses percentiles and running averages to form cluster centers directly from the data, producing smooth, interpretable market state segmentation that updates live with every bar.
Most clustering algorithms are designed for offline datasets, they require recomputation, multiple iterations, and fixed sample sizes.
SPC borrows from both statistical normalization and distance-based clustering theory , but simplifies them. Percentiles ensure that cluster centers are resistant to outliers , while the running mean provides a stable mid-point reference.
Unlike iterative methods, SPC’s centers evolve smoothly with time, ideal for charts that must update in real time without sudden reclassification noise.
SPC provides a simple yet powerful clustering heuristic that:
Runs continuously in a charting environment,
Remains interpretable and reproducible,
And allows traders to see how close the current market state is to transitioning between regimes.
Clustering by Percentiles
Traditional clustering methods find centers through iteration. SPC defines them deterministically using three simple statistics within a moving window:
Lower percentile (p_low) → captures the lower basin of feature values.
Upper percentile (p_high) → captures the upper basin.
Mean (mid) → represents the central tendency.
From these, SPC computes stable “centers”:
// K = 2 → two regimes (e.g., bullish / bearish)
=
// K = 3 → adds a neutral zone
=
These centers move gradually with the market, forming live regime boundaries without ever needing convergence steps.
Two clusters capture directional bias; three clusters add a neutral ‘range’ state.
Multi-Feature Fusion
While SPC can cluster a single feature such as RSI, CCI, Fisher Transform, DMI, Z-Score, or the price-to-MA ratio (MAR), its real strength lies in feature fusion. Each feature adds a unique lens to the clustering system. By toggling features on or off, traders can test how each dimension contributes to the regime structure.
In “Clusters” mode, SPC measures how far the current bar is from each cluster center across all enabled features, averages these distances, and assigns the bar to the nearest combined center. This effectively creates a multi-dimensional regime map , where each feature contributes equally to defining the overall market state.
The fusion distance is computed as:
dist := (rsi_d * on_off(use_rsi) + cci_d * on_off(use_cci) + fis_d * on_off(use_fis) + dmi_d * on_off(use_dmi) + zsc_d * on_off(use_zsc) + mar_d * on_off(use_mar)) / (on_off(use_rsi) + on_off(use_cci) + on_off(use_fis) + on_off(use_dmi) + on_off(use_zsc) + on_off(use_mar))
Because each feature can be standardized (Z-Score), the distances remain comparable across different scales.
Fusion mode combines multiple standardized features into a single smooth regime signal.
Visualizing Proximity - The Transition Gradient
Most indicators show binary or discrete conditions (e.g., bullish/bearish). SPC goes further, it quantifies how close the current value is to flipping into the next cluster.
It measures the distances to the two nearest cluster centers and interpolates between them:
rel_pos = min_dist / (min_dist + second_min_dist)
real_clust = cluster_val + (second_val - cluster_val) * rel_pos
This real_clust output forms a continuous line that moves smoothly between clusters:
Near 0.0 → firmly within the current regime
Around 0.5 → balanced between clusters (transition zone)
Near 1.0 → about to flip into the next regime
Smooth interpolation reveals when the market is close to a regime change.
How to Tune the Parameters
SPC includes intuitive parameters to adapt sensitivity and stability:
K Clusters (2–3): Defines the number of regimes. K = 2 for trend/range distinction, K = 3 for trend/neutral transitions.
Lookback: Determines the number of past bars used for percentile and mean calculations. Higher = smoother, more stable clusters. Lower = faster reaction to new trends.
Lower / Upper Percentiles: Define what counts as “low” and “high” states. Adjust to widen or tighten cluster ranges.
Shorter lookbacks react quickly to shifts; longer lookbacks smooth the clusters.
Visual Interpretation
In “Clusters” mode, SPC plots:
A colored histogram for each cluster (red, orange, green depending on K)
Horizontal guide lines separating cluster levels
Smooth proximity transitions between states
Each bar’s color also changes based on its assigned cluster, allowing quick recognition of when the market transitions between regimes.
Cluster bands visualize regime structure and transitions at a glance.
Practical Applications
Identify market regimes (bullish, neutral, bearish) in real time
Detect early transition phases before a trend flip occurs
Fuse multiple indicators into a single consistent signal
Engineer interpretable features for machine-learning research
Build adaptive filters or hybrid signals based on cluster proximity
Final Notes
Simplified Percentile Clustering (SPC) provides a balance between mathematical rigor and visual intuition. It replaces complex iterative algorithms with a clear, deterministic logic that any trader can understand, and yet retains the multidimensional insight of a fusion-based clustering system.
Use SPC to study how different indicators align, how regimes evolve, and how transitions emerge in real time. It’s not about predicting; it’s about seeing the structure of the market unfold.
Disclaimer
This indicator is intended for educational and analytical use.
It does not generate buy or sell signals.
Historical regime transitions are not indicative of future performance.
Always validate insights with independent analysis before making trading decisions.