Liquidity Maxing [JOAT]Liquidity Maxing - Institutional Liquidity Matrix
Introduction
Liquidity Maxing is an open-source strategy for TradingView built around institutional market structure concepts. It identifies structural shifts, evaluates trades through multi-factor confluence, and implements layered risk controls.
The strategy is designed for swing trading on 4-hour timeframes, focusing on how institutional order flow manifests in price action through structure breaks, inducements, and liquidity sweeps.
Core Functionality
Liquidity Maxing performs three primary functions:
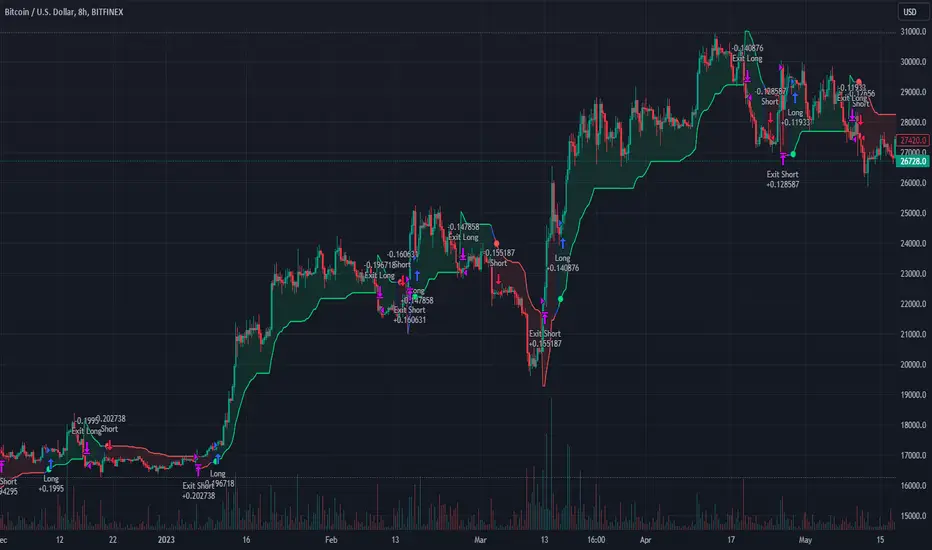
Tracks market structure to identify when control shifts between buyers and sellers
Scores potential trades using an eight-factor confluence system
Manages position sizing and risk exposure dynamically based on volatility and user-defined limits
The goal is selective trading when multiple conditions align, rather than frequent entries.
Market Structure Engine
The structure engine tracks three key events:
Break of Structure (BOS): Price pushes beyond a prior pivot in the direction of trend
Change of Character (CHoCH): Control flips from bullish to bearish or vice versa
Inducement Sweeps (IDM): Market briefly runs stops against trend before moving in the real direction
The structure module continuously updates strong highs and lows, labeling structural shifts visually. IDM markers are optional and disabled by default to maintain chart clarity.
The trade engine requires valid structure alignment before considering entries. No structure, no trade.
Eight-Factor Confluence System
Instead of relying on a single indicator, Liquidity Maxing uses an eight-factor scoring system:
Structure alignment with current trend
RSI within healthy bands (different ranges for up and down trends)
MACD momentum agreement with direction
Volume above adaptive baseline
Price relative to main trend EMA
Session and weekend filter (configurable)
Volatility expansion/contraction via ATR shifts
Higher-timeframe EMA confirmation
Each factor contributes one point to the confluence score. The default minimum confluence threshold is 6 out of 8, but you can adjust this from 1-8 based on your preference for trade frequency versus selectivity.
Only when structure and confluence agree does the strategy proceed to risk evaluation.
Dynamic Risk Management
Risk controls are implemented in multiple layers:
ATR-based stops and targets with configurable risk-to-reward ratio (default 2:1)
Volatility-adjusted position sizing to maintain consistent risk per trade as ranges expand or compress
Daily and weekly risk budgets that halt new entries once thresholds are reached
Correlation cooldown to prevent clustered trades in the same direction
Global circuit breaker with maximum drawdown limit and emergency kill switch
If any guardrail is breached, the strategy will not open new positions. The dashboard clearly displays risk state for transparency.
Market Presets
The strategy includes configuration presets optimized for different market types:
Crypto (BTC/ETH): RSI bands 70/30, volume multiplier 1.2, enhanced ATR scaling
Forex Majors: RSI bands 75/25, volume multiplier 1.5
Indices (SPY/QQQ): RSI bands 70/30, volume multiplier 1.3
Custom: Default values for user customization
For crypto assets, the strategy automatically applies ATR volatility scaling to account for higher volatility characteristics.
Monitoring and Dashboards
The strategy includes optional monitoring layers:
Risk Operations Dashboard (top-right):
Trend state
Confluence score
ATR value
Current position size percentage
Global drawdown
Daily and weekly risk consumption
Correlation guard state
Alert mode status
Performance Console (top-left):
Net profit
Current equity
Win rate percentage
Average trade value
Sharpe-style ratio (rolling 50-bar window)
Profit factor
Open trade count
Optional risk tint on chart background provides visual indication of "safe to trade" versus "halted" state.
All visualization elements can be toggled on/off from the inputs for clean chart viewing or full telemetry during parameter tuning.
Alerts and Automation
The strategy supports alert integration with two formats:
Standard alerts: Human-readable messages for long, short, and risk-halt conditions
Webhook format: JSON-formatted payloads ready for external execution systems (optional)
Alert messages are predictable and unambiguous, suitable for manual review or automated forwarding to execution engines.
Built-in Validation Suite
The strategy includes an optional validation layer that can be enabled from inputs. It checks:
Internal consistency of structure and confluence metrics
Sanity and ordering of risk parameters
Position sizing compliance with user-defined floors and caps
This validation is optional and not required for trading, but provides transparency into system operation during development or troubleshooting.
Strategy Parameters
Market Presets:
Configuration Preset: Choose between Crypto (BTC/ETH), Forex Majors, Indices (SPY/QQQ), or Custom
Market Structure Architecture:
Pivot Length: Default 5 bars
Filter by Inducement (IDM): Default enabled
Visualize Structure: Default enabled
Structure Lookback: Default 50 bars
Risk & Capital Preservation:
Risk:Reward Ratio: Default 2.0
ATR Period: Default 14
ATR Multiplier (Stop): Default 2.0
Max Drawdown Circuit Breaker: Default 10%
Risk per Trade (% Equity): Default 1.5%
Daily Risk Limit: Default 6%
Weekly Risk Limit: Default 12%
Min Position Size (% Equity): Default 0.25%
Max Position Size (% Equity): Default 5%
Correlation Cooldown (bars): Default 3
Emergency Kill Switch: Default disabled
Signal Confluence:
RSI Length: Default 14
Trend EMA: Default 200
HTF Confirmation TF: Default Daily
Allow Weekend Trading: Default enabled
Minimum Confluence Score (0-8): Default 6
Backtesting Considerations
When backtesting this strategy, consider the following:
Commission: Default 0.05% (adjustable in strategy settings)
Initial Capital: Default $100,000 (adjustable)
Position Sizing: Uses percentage of equity (default 2% per trade)
Timeframe: Optimized for 4-hour charts, though can be tested on other timeframes
Results will vary significantly based on:
Market conditions and volatility regimes
Parameter settings, especially confluence threshold
Risk limit configuration
Symbol characteristics (crypto vs forex vs equities)
Past performance does not guarantee future results. Win rate, profit factor, and other metrics should be evaluated in context of drawdown periods, trade frequency, and market conditions.
How to Use This Strategy
This is a framework that requires understanding and parameter tuning, not a one-size-fits-all solution.
Recommended workflow:
Start on 4-hour timeframe with default parameters and appropriate market preset
Run backtests and study performance console metrics: focus on drawdown behavior, win rate, profit factor, and trade frequency
Adjust confluence threshold to match your risk appetite—higher thresholds mean fewer but more selective trades
Set realistic daily and weekly risk budgets appropriate for your account size and risk tolerance
Consider ATR multiplier adjustments based on market volatility characteristics
Only connect alerts or automation after thorough testing and parameter validation
Treat this as a risk framework with an integrated entry engine, not merely an entry signal generator. The risk controls are as important as the trade signals.
Strategy Limitations
Designed for swing trading timeframes; may not perform optimally on very short timeframes
Requires sufficient market structure to identify pivots; may struggle in choppy or low-volatility environments
Crypto markets require different parameter tuning than traditional markets
Risk limits may prevent entries during favorable setups if daily/weekly budgets are exhausted
Correlation cooldown may delay entries that would otherwise be valid
Backtesting results depend on data quality and may not reflect live trading with slippage
Design Philosophy
Many indicators tell you when price crossed a moving average or RSI left oversold. This strategy addresses questions institutional traders ask:
Who is in control of the market right now?
Is this move structurally significant or just noise?
Do I want to add more risk given what I've already done today/week?
If I'm wrong, exactly how painful can this be?
The strategy provides disciplined, repeatable answers to these questions through systematic structure analysis, confluence filtering, and multi-layer risk management.
Technical Implementation
The strategy uses Pine Script v6 with:
Custom types for structure, confluence, and risk state management
Functional programming approach for reusable calculations
State management through persistent variables
Optional visual elements that can be toggled independently
The code is open-source and can be modified to suit individual needs. All important logic is visible in the source code.
Disclaimer
This script is provided for educational and informational purposes only. It is not intended as financial, investment, trading, or any other type of advice or recommendation. Trading involves substantial risk of loss and is not suitable for all investors. Past performance, whether real or indicated by historical tests of strategies, is not indicative of future results.
No representation is being made that any account will or is likely to achieve profits or losses similar to those shown. In fact, there are frequently sharp differences between backtested results and actual results subsequently achieved by any particular trading strategy.
The user should be aware of the risks involved in trading and should trade only with risk capital. The authors and publishers of this script are not responsible for any losses or damages, including without limitation, any loss of profit, which may arise directly or indirectly from use of or reliance on this script.
This strategy uses technical analysis methods and indicators that are not guaranteed to be accurate or profitable. Market conditions change, and strategies that worked in the past may not work in the future. Users should thoroughly test any strategy in a paper trading environment before risking real capital.
Commission and slippage settings in backtests may not accurately reflect live trading conditions. Real trading results will vary based on execution quality, market liquidity, and other factors not captured in backtesting.
The user assumes full responsibility for all trading decisions made using this script. Always consult with a qualified financial advisor before making investment decisions.
Enjoy - officialjackofalltrades
אסטרטגיית Pine Script®