Finite Difference - Backward (mcbw_)In calculus there exists a 'derivative', which simply just measures the difference between two points on a curve. For well behaved mathematical functions there are infinitely many points and so there exists a derivative at every point. Where there are infinitely many points in a curve that curve is called 'continuous'. Continuous curves are very nice to deal with since each point on it exists almost exactly where its neighbors are. However, if the curve does not have infinitely many points on it, but instead has a finite number of points on it, that curve is called 'discrete' instead of continuous. Taking the derivative of discrete curves is much trickier business since there are none of the mathematical conveniences that a continuous offers. In the real world everything we measure is a discrete curve, including Price (since we measure it a finite number of times, aka each candlestick)!
The branch of Discrete Mathematics has found an approach to measure the derivative along a discrete curve, that approach is aptly called " Finite Difference ". To get a more accurate approximation of a discrete derivative, the finite difference approach uses weighted combinations of neighboring points. The most common type of finite difference is a 'central' difference, this uses a combination of points before and after the point of interest to approximate the discrete derivative. This is great for historical analysis but is not of much use for trading algorithms since it technically means using future prices to calculate the derivative of the current point. Instead we can use a less common variant called a ' Backwards Difference ' that only uses a combination of points before the current one to help approximate the current derivative.
In this script you can choose the " Order " of your derivative and the " Accuracy " of its approximation. This script is for educational purposes for folks building trading algorithms. Many trading algorithms often have an element of seeing how much Price has changed from the previous candle to the current candle. This approach is the lowest accuracy derivative possible, and using the backwards finite differences, made available for the first time on TradingView (!!), algorithms that use derivatives can now have higher orders of accuracy!
Happy Trading/Developing!
חפש סקריפטים עבור "algo"
Accurate Bollinger Bands mcbw_ [True Volatility Distribution]The Bollinger Bands have become a very important technical tool for discretionary and algorithmic traders alike over the last decades. It was designed to give traders an edge on the markets by setting probabilistic values to different levels of volatility. However, some of the assumptions that go into its calculations make it unusable for traders who want to get a correct understanding of the volatility that the bands are trying to be used for. Let's go through what the Bollinger Bands are said to show, how their calculations work, the problems in the calculations, and how the current indicator I am presenting today fixes these.
--> If you just want to know how the settings work then skip straight to the end or click on the little (i) symbol next to the values in the indicator settings window when its on your chart <--
--------------------------- What Are Bollinger Bands ---------------------------
The Bollinger Bands were formed in the 1980's, a time when many retail traders interacted with their symbols via physically printed charts and computer memory for personal computer memory was measured in Kb (about a factor of 1 million smaller than today). Bollinger Bands are designed to help a trader or algorithm see the likelihood of price expanding outside of its typical range, the further the lines are from the current price implies the less often they will get hit. With a hands on understanding many strategies use these levels for designated levels of breakout trades or to assist in defining price ranges.
--------------------------- How Bollinger Bands Work ---------------------------
The calculations that go into Bollinger Bands are rather simple. There is a moving average that centers the indicator and an equidistant top band and bottom band are drawn at a fixed width away. The moving average is just a typical moving average (or common variant) that tracks the price action, while the distance to the top and bottom bands is a direct function of recent price volatility. The way that the distance to the bands is calculated is inspired by formulas from statistics. The standard deviation is taken from the candles that go into the moving average and then this is multiplied by a user defined value to set the bands position, I will call this value 'the multiple'. When discussing Bollinger Bands, that trading community at large normally discusses 'the multiple' as a multiplier of the standard deviation as it applies to a normal distribution (gaußian probability). On a normal distribution the number of standard deviations away (which trades directly use as 'the multiple') you are directly corresponds to how likely/unlikely something is to happen:
1 standard deviation equals 68.3%, meaning that the price should stay inside the 1 standard deviation 68.3% of the time and be outside of it 31.7% of the time;
2 standard deviation equals 95.5%, meaning that the price should stay inside the 2 standard deviation 95.5% of the time and be outside of it 4.5% of the time;
3 standard deviation equals 99.7%, meaning that the price should stay inside the 3 standard deviation 99.7% of the time and be outside of it 0.3% of the time.
Therefore when traders set 'the multiple' to 2, they interpret this as meaning that price will not reach there 95.5% of the time.
---------------- The Problem With The Math of Bollinger Bands ----------------
In and of themselves the Bollinger Bands are a great tool, but they have become misconstrued with some incorrect sense of statistical meaning, when they should really just be taken at face value without any further interpretation or implication.
In order to explain this it is going to get a bit technical so I will give a little math background and try to simplify things. First let's review some statistics topics (distributions, percentiles, standard deviations) and then with that understanding explore the incorrect logic of how Bollinger Bands have been interpreted/employed.
---------------- Quick Stats Review ----------------
.
(If you are comfortable with statistics feel free to skip ahead to the next section)
.
-------- I: Probability distributions --------
When you have a lot of data it is helpful to see how many times different results appear in your dataset. To visualize this people use "histograms", which just shows how many times each element appears in the dataset by stacking each of the same elements on top of each other to form a graph. You may be familiar with the bell curve (also called the "normal distribution", which we will be calling it by). The normal distribution histogram looks like a big hump around zero and then drops off super quickly the further you get from it. This shape (the bell curve) is very nice because it has a lot of very nifty mathematical properties and seems to show up in nature all the time. Since it pops up in so many places, society has developed many different shortcuts related to it that speed up all kinds of calculations, including the shortcut that 1 standard deviation = 68.3%, 2 standard deviations = 95.5%, and 3 standard deviations = 99.7% (these only apply to the normal distribution). Despite how handy the normal distribution is and all the shortcuts we have for it are, and how much it shows up in the natural world, there is nothing that forces your specific dataset to look like it. In fact, your data can actually have any possible shape. As we will explore later, economic and financial datasets *rarely* follow the normal distribution.
-------- II: Percentiles --------
After you have made the histogram of your dataset you have built the "probability distribution" of your own dataset that is specific to all the data you have collected. There is a whole complicated framework for how to accurately calculate percentiles but we will dramatically simplify it for our use. The 'percentile' in our case is just the number of data points we are away from the "middle" of the data set (normally just 0). Lets say I took the difference of the daily close of a symbol for the last two weeks, green candles would be positive and red would be negative. In this example my dataset of day by day closing price difference is:
week 1:
week 2:
sorting all of these value into a single dataset I have:
I can separate the positive and negative returns and explore their distributions separately:
negative return distribution =
positive return distribution =
Taking the 25th% percentile of these would just be taking the value that is 25% towards the end of the end of these returns. Or akin the 100%th percentile would just be taking the vale that is 100% at the end of those:
negative return distribution (50%) = -5
positive return distribution (50%) = +4
negative return distribution (100%) = -10
positive return distribution (100%) = +20
Or instead of separating the positive and negative returns we can also look at all of the differences in the daily close as just pure price movement and not account for the direction, in this case we would pool all of the data together by ignoring the negative signs of the negative reruns
combined return distribution =
In this case the 50%th and 100%th percentile of the combined return distribution would be:
combined return distribution (50%) = 4
combined return distribution (100%) = 10
Sometimes taking the positive and negative distributions separately is better than pooling them into a combined distribution for some purposes. Other times the combined distribution is better.
Most financial data has very different distributions for negative returns and positive returns. This is encapsulated in sayings like "Price takes the stairs up and the elevator down".
-------- III: Standard Deviation --------
The formula for the standard deviation (refereed to here by its shorthand 'STDEV') can be intimidating, but going through each of its elements will illuminate what it does. The formula for STDEV is equal to:
square root ( (sum ) / N )
Going back the the dataset that you might have, the variables in the formula above are:
'mean' is the average of your entire dataset
'x' is just representative of a single point in your dataset (one point at a time)
'N' is the total number of things in your dataset.
Going back to the STDEV formula above we can see how each part of it works. Starting with the '(x - mean)' part. What this does is it takes every single point of the dataset and measure how far away it is from the mean of the entire dataset. Taking this value to the power of two: '(x - mean) ^ 2', means that points that are very far away from the dataset mean get 'penalized' twice as much. Points that are very close to the dataset mean are not impacted as much. In practice, this would mean that if your dataset had a bunch of values that were in a wide range but always stayed in that range, this value ('(x - mean) ^ 2') would end up being small. On the other hand, if your dataset was full of the exact same number, but had a couple outliers very far away, this would have a much larger value since the square par of '(x - mean) ^ 2' make them grow massive. Now including the sum part of 'sum ', this just adds up all the of the squared distanced from the dataset mean. Then this is divided by the number of values in the dataset ('N'), and then the square root of that value is taken.
There is nothing inherently special or definitive about the STDEV formula, it is just a tool with extremely widespread use and adoption. As we saw here, all the STDEV formula is really doing is measuring the intensity of the outliers.
--------------------------- Flaws of Bollinger Bands ---------------------------
The largest problem with Bollinger Bands is the assumption that price has a normal distribution. This is assumption is massively incorrect for many reasons that I will try to encapsulate into two points:
Price return do not follow a normal distribution, every single symbol on every single timeframe has is own unique distribution that is specific to only itself. Therefore all the tools, shortcuts, and ideas that we use for normal distributions do not apply to price returns, and since they do not apply here they should not be used. A more general approach is needed that allows each specific symbol on every specific timeframe to be treated uniquely.
The distributions of price returns on the positive and negative side are almost never the same. A more general approach is needed that allows positive and negative returns to be calculated separately.
In addition to the issues of the normal distribution assumption, the standard deviation formula (as shown above in the quick stats review) is essentially just a tame measurement of outliers (a more aggressive form of outlier measurement might be taking the differences to the power of 3 rather than 2). Despite this being a bit of a philosophical question, does the measurement of outlier intensity as defined by the STDEV formula really measure what we want to know as traders when we're experiencing volatility? Or would adjustments to that formula better reflect what we *experience* as volatility when we are actively trading? This is an open ended question that I will leave here, but I wanted to pose this question because it is a key part of what how the Bollinger Bands work that we all assume as a given.
Circling back on the normal distribution assumption, the standard deviation formula used in the calculation of the bands only encompasses the deviation of the candles that go into the moving average and have no knowledge of the historical price action. Therefore the level of the bands may not really reflect how the price action behaves over a longer period of time.
------------ Delivering Factually Accurate Data That Traders Need------------
In light of the problems identified above, this indicator fixes all of these issue and delivers statistically correct information that discretionary and algorithmic traders can use, with truly accurate probabilities. It takes the price action of the last 2,000 candles and builds a huge dataset of distributions that you can directly select your percentiles from. It also allows you to have the positive and negative distributions calculated separately, or if you would like, you can pool all of them together in a combined distribution. In addition to this, there is a wide selection of moving averages directly available in the indicator to choose from.
Hedge funds, quant shops, algo prop firms, and advanced mechanical groups all employ the true return distributions in their work. Now you have access to the same type of data with this indicator, wherein it's doing all the lifting for you.
------------------------------ Indicator Settings ------------------------------
.
---- Moving average ----
Select the type of moving average you would like and its length
---- Bands ----
The percentiles that you enter here will be pulled directly from the return distribution of the last 2,000 candles. With the typical Bollinger Bands, traders would select 2 standard deviations and incorrectly think that the levels it highlights are the 95.5% levels. Now, if you want the true 95.5% level, you can just enter 95.5 into the percentile value here. Each of the three available bands takes the true percentile you enter here.
---- Separate Positive & Negative Distributions----
If this box is checked the positive and negative distributions are treated indecently, completely separate from each other. You will see that the width of the top and bottom bands will be different for each of the percentiles you enter.
If this box is unchecked then all the negative and positive distributions are pooled together. You will notice that the width of the top and bottom bands will be the exact same.
---- Distribution Size ----
This is the number of candles that the price return is calculated over. EG: to collect the price return over the last 33 candles, the difference of price from now to 33 candles ago is calculated for the last 2,000 candles, to build a return distribution of 2000 points of price differences over 33 candles.
NEGATIVE NUMBERS(<0) == exact number of candles to include;
EG: setting this value to -20 will always collect volatility distributions of 20 candles
POSITIVE NUMBERS(>0) == number of candles to include as a multiple of the Moving Average Length value set above;
EG: if the Moving Average Length value is set to 22, setting this value to 2 will use the last 22*2 = 44 candles for the collection of volatility distributions
MORE candles being include will generally make the bands WIDER and their size will change SLOWER over time.
I wish you focus, dedication, and earnest success on your journey.
Happy trading :)

AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend)The AiTrend Pattern Matrix for kNN Forecasting (AiBitcoinTrend) is a cutting-edge indicator that combines advanced mathematical modeling, AI-driven analytics, and segment-based pattern recognition to forecast price movements with precision. This tool is designed to provide traders with deep insights into market dynamics by leveraging multivariate pattern detection and sophisticated predictive algorithms.
👽 Core Features
Segment-Based Pattern Recognition
At its heart, the indicator divides price data into discrete segments, capturing key elements like candle bodies, high-low ranges, and wicks. These segments are normalized using ATR-based volatility adjustments to ensure robustness across varying market conditions.
AI-Powered k-Nearest Neighbors (kNN) Prediction
The predictive engine uses the kNN algorithm to identify the closest historical patterns in a multivariate dictionary. By calculating the distance between current and historical segments, the algorithm determines the most likely outcomes, weighting predictions based on either proximity (distance) or averages.
Dynamic Dictionary of Historical Patterns
The indicator maintains a rolling dictionary of historical patterns, storing multivariate data for:
Candle body ranges, High-low ranges, Wick highs and lows.
This dynamic approach ensures the model adapts continuously to evolving market conditions.
Volatility-Normalized Forecasting
Using ATR bands, the indicator normalizes patterns, reducing noise and enhancing the reliability of predictions in high-volatility environments.
AI-Driven Trend Detection
The indicator not only predicts price levels but also identifies market regimes by comparing current conditions to historically significant highs, lows, and midpoints. This allows for clear visualizations of trend shifts and momentum changes.
👽 Deep Dive into the Core Mathematics
👾 Segment-Based Multivariate Pattern Analysis
The indicator analyzes price data by dividing each bar into distinct segments, isolating key components such as:
Body Ranges: Differences between the open and close prices.
High-Low Ranges: Capturing the full volatility of a bar.
Wick Extremes: Quantifying deviations beyond the body, both above and below.
Each segment contributes uniquely to the predictive model, ensuring a rich, multidimensional understanding of price action. These segments are stored in a rolling dictionary of patterns, enabling the indicator to reference historical behavior dynamically.
👾 Volatility Normalization Using ATR
To ensure robustness across varying market conditions, the indicator normalizes patterns using Average True Range (ATR). This process scales each component to account for the prevailing market volatility, allowing the algorithm to compare patterns on a level playing field regardless of differing price scales or fluctuations.
👾 k-Nearest Neighbors (kNN) Algorithm
The AI core employs the kNN algorithm, a machine-learning technique that evaluates the similarity between the current pattern and a library of historical patterns.
Euclidean Distance Calculation:
The indicator computes the multivariate distance across four distinct dimensions: body range, high-low range, wick low, and wick high. This ensures a comprehensive and precise comparison between patterns.
Weighting Schemes: The contribution of each pattern to the forecast is either weighted by its proximity (distance) or averaged, based on user settings.
👾 Prediction Horizon and Refinement
The indicator forecasts future price movements (Y_hat) by predicting logarithmic changes in the price and projecting them forward using exponential scaling. This forecast is smoothed using a user-defined EMA filter to reduce noise and enhance actionable clarity.
👽 AI-Driven Pattern Recognition
Dynamic Dictionary of Patterns: The indicator maintains a rolling dictionary of N multivariate patterns, continuously updated to reflect the latest market data. This ensures it adapts seamlessly to changing market conditions.
Nearest Neighbor Matching: At each bar, the algorithm identifies the most similar historical pattern. The prediction is based on the aggregated outcomes of the closest neighbors, providing confidence levels and directional bias.
Multivariate Synthesis: By combining multiple dimensions of price action into a unified prediction, the indicator achieves a level of depth and accuracy unattainable by single-variable models.
Visual Outputs
Forecast Line (Y_hat_line):
A smoothed projection of the expected price trend, based on the weighted contribution of similar historical patterns.
Trend Regime Bands:
Dynamic high, low, and midlines highlight the current market regime, providing actionable insights into momentum and range.
Historical Pattern Matching:
The nearest historical pattern is displayed, allowing traders to visualize similarities
👽 Applications
Trend Identification:
Detect and follow emerging trends early using dynamic trend regime analysis.
Reversal Signals:
Anticipate market reversals with high-confidence predictions based on historically similar scenarios.
Range and Momentum Trading:
Leverage multivariate analysis to understand price ranges and momentum, making it suitable for both breakout and mean-reversion strategies.
Disclaimer: This information is for entertainment purposes only and does not constitute financial advice. Please consult with a qualified financial advisor before making any investment decisions.

Bayesian Price Projection Model [Pinescriptlabs]📊 Dynamic Price Projection Algorithm 📈
This algorithm combines **statistical calculations**, **technical analysis**, and **Bayesian theory** to forecast a future price while providing **uncertainty ranges** that represent upper and lower bounds. The calculations are designed to adjust projections by considering market **trends**, **volatility**, and the historical probabilities of reaching new highs or lows.
Here’s how it works:
🚀 Future Price Projection
A dynamic calculation estimates the future price based on three key elements:
1. **Trend**: Defines whether the market is predisposed to move up or down.
2. **Volatility**: Quantifies the magnitude of the expected change based on historical fluctuations.
3. **Time Factor**: Uses the logarithm of the projected period (`proyeccion_dias`) to adjust how time impacts the estimate.
🧠 **Bayesian Probabilistic Adjustment**
- Conditional probabilities are calculated using **Bayes' formula**:
\
This models future events using conditional information:
- **Probability of reaching a new all-time high** if the price is trending upward.
- **Probability of reaching a new all-time low** if the price is trending downward.
- These probabilities refine the future price estimate by considering:
- **Higher volatility** increases the likelihood of hitting extreme levels (highs/lows).
- **Market trends** influence the expected price movement direction.
🌟 **Volatility Calculation**
- Volatility is measured using the **ATR (Average True Range)** indicator with a 14-period window. This reflects the average amplitude of price fluctuations.
- To express volatility as a percentage, the ATR is normalized by dividing it by the closing price and multiplying it by 200.
- Volatility is then categorized into descriptive levels (e.g., **Very Low**, **Low**, **Moderate**, etc.) for better interpretation.
---
🎯 **Deviation Limits (Upper and Lower)**
- The upper and lower limits form a **projected range** around the estimated future price, providing a framework for uncertainty.
- These limits are calculated by adjusting the ATR using:
- A user-defined **multiplier** (`factor_desviacion`).
- **Bayesian probabilities** calculated earlier.
- The **square root of the projected period** (`proyeccion_dias`), incorporating the principle that uncertainty grows over time.
🔍 **Interpreting the Model**
This can be seen as a **dynamic probabilistic model** that:
- Combines **technical analysis** (trends and ATR).
- Refines probabilities using **Bayesian theory**.
- Provides a **visual projection range** to help you understand potential future price movements and associated uncertainties.
⚡ Whether you're analyzing **volatile markets** or confirming **bullish/bearish scenarios**, this tool equips you with a robust, data-driven approach! 🚀
Español :
📊 Algoritmo de Proyección de Precio Dinámico 📈
Este algoritmo combina **cálculos estadísticos**, **análisis técnico** y **la teoría de Bayes** para proyectar un precio futuro, junto con rangos de **incertidumbre** que representan los límites superior e inferior. Los cálculos están diseñados para ajustar las proyecciones considerando la **tendencia del mercado**, **volatilidad** y las probabilidades históricas de alcanzar nuevos máximos o mínimos.
Aquí se explica su funcionamiento:
🚀 **Proyección de Precio Futuro**
Se realiza un cálculo dinámico del precio futuro estimado basado en tres elementos clave:
1. **Tendencia**: Define si el mercado tiene predisposición a subir o bajar.
2. **Volatilidad**: Determina la magnitud del cambio esperado en función de las fluctuaciones históricas.
3. **Factor de Tiempo**: Usa el logaritmo del período proyectado (`proyeccion_dias`) para ajustar cómo el tiempo afecta la estimación.
🧠 **Ajuste Probabilístico con la Teoría de Bayes**
- Se calculan probabilidades condicionales mediante la fórmula de **Bayes**:
\
Esto permite modelar eventos futuros considerando información condicional:
- **Probabilidad de alcanzar un nuevo máximo histórico** si el precio sube.
- **Probabilidad de alcanzar un nuevo mínimo histórico** si el precio baja.
- Estas probabilidades ajustan la estimación del precio futuro considerando:
- **Mayor volatilidad** aumenta la probabilidad de alcanzar niveles extremos (máximos/mínimos).
- **La tendencia del mercado** afecta la dirección esperada del movimiento del precio.
🌟 **Cálculo de Volatilidad**
- La volatilidad se mide usando el indicador **ATR (Average True Range)** con un período de 14 velas. Este indicador refleja la amplitud promedio de las fluctuaciones del precio.
- Para obtener un valor porcentual, el ATR se normaliza dividiéndolo por el precio de cierre y multiplicándolo por 200.
- Además, se clasifica esta volatilidad en categorías descriptivas (e.g., **Muy Baja**, **Baja**, **Moderada**, etc.) para facilitar su interpretación.
🎯 **Límites de Desviación (Superior e Inferior)**
- Los límites superior e inferior representan un **rango proyectado** en torno al precio futuro estimado, proporcionando un marco para la incertidumbre.
- Estos límites se calculan ajustando el ATR según:
- Un **multiplicador** definido por el usuario (`factor_desviacion`).
- Las **probabilidades condicionales** calculadas previamente.
- La **raíz cuadrada del período proyectado** (`proyeccion_dias`), lo que incorpora el principio de que la incertidumbre aumenta con el tiempo.
---
🔍 **Interpretación del Modelo**
Este modelo se puede interpretar como un **modelo probabilístico dinámico** que:
- Integra **análisis técnico** (tendencias y ATR).
- Ajusta probabilidades utilizando **la teoría de Bayes**.
- Proporciona un **rango de proyección visual** para ayudarte a entender los posibles movimientos futuros del precio y su incertidumbre.
⚡ Ya sea que estés analizando **mercados volátiles** o confirmando **escenarios alcistas/bajistas**, ¡esta herramienta te ofrece un enfoque robusto y basado en datos! 🚀

Market Trades PinescriptlabsThis algorithm is designed to emulate the true order book of exchanges by showing the quantity of transactions of an asset in real-time, while identifying patterns of high activity and volatility in the market through the analysis of volume and price movements. 📈 Below, I explain how to understand and use the information provided by the chart, along with the trades table:
Identification of High Activity Zones 🚀
The algorithm calculates the average volume and the rate of price change to detect areas with spikes in activity. This is visualized on the chart with labels "Volatility Spike Buy" and "Volatility Spike Sell":
Volatility Spike Buy: Indicates an unusual increase in volatility in the buying market, suggesting a potential surge in buying interest. 🟢
Volatility Spike Sell: Signals an increase in volatility in the selling market, which may indicate selling pressure or a sudden massive sell-off. 🔴
Market Trades Table 📋
The table provides a detailed view of the latest trades:
Price: Displays the price at which each trade was executed. 💵
Quantity (Traded): Indicates the amount of the asset traded. 💰
Type of Trade (Buy/Sell): Differentiates between buy (Buy) and sell (Sell) operations based on volume and strength. 🔄
Date and Time: Refers to the start of the calculated trading candle. ⏰
Recency: Identifies the most recent trade to facilitate tracking of current activity. 🔍
Analysis of Trade Imbalance ⚖️
The imbalance between buys and sells is calculated based on the volume of both. This indicator helps to understand whether the market has a tendency toward buying or selling, showing if there is greater strength on one side of the market.
A positive imbalance suggests more buying pressure. 📊
A negative imbalance indicates greater selling pressure. 📉
Volume Presentation
Visualizes the volume of buying and selling in the market, allowing the identification of buying or selling strength through the size of the volume candle. 🔍
Español :
"Este algoritmo está diseñado para emular el verdadero libro de órdenes de los intercambios al mostrar la cantidad de transacciones de un activo en tiempo real, mientras identifica patrones de alta actividad y volatilidad en el mercado a través del análisis de volumen y movimientos de precios. 📈 A continuación, explico cómo entender y usar la información proporcionada por el gráfico, junto con la tabla de operaciones:"
Identificación de Zonas de Alta Actividad 🚀
El algoritmo calcula el volumen promedio y la velocidad de cambio de precio para detectar zonas con picos de actividad. Esto se visualiza en el gráfico con etiquetas de "Volatility Spike Buy" y "Volatility Spike Sell":
Volatility Spike Buy: Indica un incremento inusual de volatilidad en el mercado de compra, sugiriendo un posible interés de compra elevado. 🟢
Volatility Spike Sell: Señala un incremento de volatilidad en el mercado de venta, lo cual puede indicar presión de venta o una venta masiva repentina. 🔴
Tabla de Operaciones en el Mercado (Market Trades) 📋
La tabla proporciona una vista detallada de las últimas operaciones:
Precio: Muestra el precio al cual se realizó cada operación. 💵
Cantidad (Transaccionada): Indica la cantidad del activo transaccionada. 💰
Tipo de operación (Buy/Sell): Diferencia entre operaciones de compra (Buy) y de venta (Sell), dependiendo del volumen y fuerza. 🔄
Fecha y Hora: Refleja el inicio de la vela de negociación calculada. ⏰
Recency: Identifica la operación más reciente para facilitar el seguimiento de la actividad actual. 🔍
Análisis de Desequilibrio de Operaciones (Imbalance) ⚖️
El desequilibrio entre compras y ventas se calcula con base en el volumen de ambas. Este indicador ayuda a entender si el mercado tiene una tendencia hacia la compra o venta, mostrando si hay una mayor fuerza en uno de los lados del mercado.
Un desequilibrio positivo sugiere más presión de compra. 📊
Un desequilibrio negativo indica mayor presión de venta. 📉
Presentación en Volumen
Visualiza el volumen de compra y venta en el mercado, permitiendo identificar mediante el tamaño de la vela de volumen la fuerza, ya sea compradora o vendedora. 🔍

KNN OscillatorOverview
The KNN Oscillator is an advanced technical analysis tool designed to help traders identify potential trend reversals and market momentum. Using the K-Nearest Neighbors (KNN) algorithm, this oscillator normalizes KNN values to create a dynamic and responsive indicator. The oscillator line changes color to reflect the market sentiment, providing clear visual cues for trading decisions.
Key Features
Dynamic Color Oscillator: The line changes color based on the oscillator value – green for positive, red for negative, and grey for neutral.
Advanced KNN Algorithm: Utilizes the K-Nearest Neighbors algorithm for precise trend detection.
Normalized Values: Ensures the oscillator values are normalized to align with the stock price range, making it applicable to various assets.
Easy Integration: Can be easily added to any TradingView chart for enhanced analysis.
How It Works
The KNN Oscillator leverages the K-Nearest Neighbors algorithm to calculate the average distance of the nearest neighbors over a specified period. These values are then normalized to match the stock price range, ensuring they are comparable across different assets. The oscillator value is derived by taking the difference between the normalized KNN values and the source price. The line's color changes dynamically to provide an immediate visual indication of the market's state:
Green: Positive values indicate upward momentum.
Red: Negative values indicate downward momentum.
Grey: Neutral values indicate a stable or consolidating market.
Usage Instructions
Trend Reversal Detection: Use the color changes to identify potential trend reversals. A shift from red to green suggests a bullish reversal, while a shift from green to red indicates a bearish reversal.
Momentum Analysis: The oscillator's value and color help gauge market momentum. Strong positive values (green) indicate strong upward momentum, while strong negative values (red) indicate strong downward momentum.
Market Sentiment: The dynamic color changes provide an easy-to-understand visual representation of market sentiment, helping traders make informed decisions quickly.
Confirmation Tool: Use the KNN Oscillator in conjunction with other technical indicators to confirm signals and improve the accuracy of your trades.
Scalability: Applicable to various timeframes and asset classes, making it a versatile tool for all types of traders.

Support & Resistance AI (K means/median) [ThinkLogicAI]█ OVERVIEW
K-means is a clustering algorithm commonly used in machine learning to group data points into distinct clusters based on their similarities. While K-means is not typically used directly for identifying support and resistance levels in financial markets, it can serve as a tool in a broader analysis approach.
Support and resistance levels are price levels in financial markets where the price tends to react or reverse. Support is a level where the price tends to stop falling and might start to rise, while resistance is a level where the price tends to stop rising and might start to fall. Traders and analysts often look for these levels as they can provide insights into potential price movements and trading opportunities.
█ BACKGROUND
The K-means algorithm has been around since the late 1950s, making it more than six decades old. The algorithm was introduced by Stuart Lloyd in his 1957 research paper "Least squares quantization in PCM" for telecommunications applications. However, it wasn't widely known or recognized until James MacQueen's 1967 paper "Some Methods for Classification and Analysis of Multivariate Observations," where he formalized the algorithm and referred to it as the "K-means" clustering method.
So, while K-means has been around for a considerable amount of time, it continues to be a widely used and influential algorithm in the fields of machine learning, data analysis, and pattern recognition due to its simplicity and effectiveness in clustering tasks.
█ COMPARE AND CONTRAST SUPPORT AND RESISTANCE METHODS
1) K-means Approach:
Cluster Formation: After applying the K-means algorithm to historical price change data and visualizing the resulting clusters, traders can identify distinct regions on the price chart where clusters are formed. Each cluster represents a group of similar price change patterns.
Cluster Analysis: Analyze the clusters to identify areas where clusters tend to form. These areas might correspond to regions of price behavior that repeat over time and could be indicative of support and resistance levels.
Potential Support and Resistance Levels: Based on the identified areas of cluster formation, traders can consider these regions as potential support and resistance levels. A cluster forming at a specific price level could suggest that this level has been historically significant, causing similar price behavior in the past.
Cluster Standard Deviation: In addition to looking at the means (centroids) of the clusters, traders can also calculate the standard deviation of price changes within each cluster. Standard deviation is a measure of the dispersion or volatility of data points around the mean. A higher standard deviation indicates greater price volatility within a cluster.
Low Standard Deviation: If a cluster has a low standard deviation, it suggests that prices within that cluster are relatively stable and less likely to exhibit sudden and large price movements. Traders might consider placing tighter stop-loss orders for trades within these clusters.
High Standard Deviation: Conversely, if a cluster has a high standard deviation, it indicates greater price volatility within that cluster. Traders might opt for wider stop-loss orders to allow for potential price fluctuations without getting stopped out prematurely.
Cluster Density: Each data point is assigned to a cluster so a cluster that is more dense will act more like gravity and
2) Traditional Approach:
Trendlines: Draw trendlines connecting significant highs or lows on a price chart to identify potential support and resistance levels.
Chart Patterns: Identify chart patterns like double tops, double bottoms, head and shoulders, and triangles that often indicate potential reversal points.
Moving Averages: Use moving averages to identify levels where the price might find support or resistance based on the average price over a specific period.
Psychological Levels: Identify round numbers or levels that traders often pay attention to, which can act as support and resistance.
Previous Highs and Lows: Identify significant previous price highs and lows that might act as support or resistance.
The key difference lies in the approach and the foundation of these methods. Traditional methods are based on well-established principles of technical analysis and market psychology, while the K-means approach involves clustering price behavior without necessarily incorporating market sentiment or specific price patterns.
It's important to note that while the K-means approach might provide an interesting way to analyze price data, it should be used cautiously and in conjunction with other traditional methods. Financial markets are influenced by a wide range of factors beyond just price behavior, and the effectiveness of any method for identifying support and resistance levels should be thoroughly tested and validated. Additionally, developments in trading strategies and analysis techniques could have occurred since my last update.
█ K MEANS ALGORITHM
The algorithm for K means is as follows:
Initialize cluster centers
assign data to clusters based on minimum distance
calculate cluster center by taking the average or median of the clusters
repeat steps 1-3 until cluster centers stop moving
█ LIMITATIONS OF K MEANS
There are 3 main limitations of this algorithm:
Sensitive to Initializations: K-means is sensitive to the initial placement of centroids. Different initializations can lead to different cluster assignments and final results.
Assumption of Equal Sizes and Variances: K-means assumes that clusters have roughly equal sizes and spherical shapes. This may not hold true for all types of data. It can struggle with identifying clusters with uneven densities, sizes, or shapes.
Impact of Outliers: K-means is sensitive to outliers, as a single outlier can significantly affect the position of cluster centroids. Outliers can lead to the creation of spurious clusters or distortion of the true cluster structure.
█ LIMITATIONS IN APPLICATION OF K MEANS IN TRADING
Trading data often exhibits characteristics that can pose challenges when applying indicators and analysis techniques. Here's how the limitations of outliers, varying scales, and unequal variance can impact the use of indicators in trading:
Outliers are data points that significantly deviate from the rest of the dataset. In trading, outliers can represent extreme price movements caused by rare events, news, or market anomalies. Outliers can have a significant impact on trading indicators and analyses:
Indicator Distortion: Outliers can skew the calculations of indicators, leading to misleading signals. For instance, a single extreme price spike could cause indicators like moving averages or RSI (Relative Strength Index) to give false signals.
Risk Management: Outliers can lead to overly aggressive trading decisions if not properly accounted for. Ignoring outliers might result in unexpected losses or missed opportunities to adjust trading strategies.
Different Scales: Trading data often includes multiple indicators with varying units and scales. For example, prices are typically in dollars, volume in units traded, and oscillators have their own scale. Mixing indicators with different scales can complicate analysis:
Normalization: Indicators on different scales need to be normalized or standardized to ensure they contribute equally to the analysis. Failure to do so can lead to one indicator dominating the analysis due to its larger magnitude.
Comparability: Without normalization, it's challenging to directly compare the significance of indicators. Some indicators might have a larger numerical range and could overshadow others.
Unequal Variance: Unequal variance in trading data refers to the fact that some indicators might exhibit higher volatility than others. This can impact the interpretation of signals and the performance of trading strategies:
Volatility Adjustment: When combining indicators with varying volatility, it's essential to adjust for their relative volatilities. Failure to do so might lead to overemphasizing or underestimating the importance of certain indicators in the trading strategy.
Risk Assessment: Unequal variance can impact risk assessment. Indicators with higher volatility might lead to riskier trading decisions if not properly taken into account.
█ APPLICATION OF THIS INDICATOR
This indicator can be used in 2 ways:
1) Make a directional trade:
If a trader thinks price will go higher or lower and price is within a cluster zone, The trader can take a position and place a stop on the 1 sd band around the cluster. As one can see below, the trader can go long the green arrow and place a stop on the one standard deviation mark for that cluster below it at the red arrow. using this we can calculate a risk to reward ratio.
Calculating risk to reward: targeting a risk reward ratio of 2:1, the trader could clearly make that given that the next resistance area above that in the orange cluster exceeds this risk reward ratio.
2) Take a reversal Trade:
We can use cluster centers (support and resistance levels) to go in the opposite direction that price is currently moving in hopes of price forming a pivot and reversing off this level.
Similar to the directional trade, we can use the standard deviation of the cluster to place a stop just in case we are wrong.
In this example below we can see that shorting on the red arrow and placing a stop at the one standard deviation above this cluster would give us a profitable trade with minimal risk.
Using the cluster density table in the upper right informs the trader just how dense the cluster is. Higher density clusters will give a higher likelihood of a pivot forming at these levels and price being rejected and switching direction with a larger move.
█ FEATURES & SETTINGS
General Settings:
Number of clusters: The user can select from 3 to five clusters. A good rule of thumb is that if you are trading intraday, less is more (Think 3 rather than 5). For daily 4 to 5 clusters is good.
Cluster Method: To get around the outlier limitation of k means clustering, The median was added. This gives the user the ability to choose either k means or k median clustering. K means is the preferred method if the user things there are no large outliers, and if there appears to be large outliers or it is assumed there are then K medians is preferred.
Bars back To train on: This will be the amount of bars to include in the clustering. This number is important so that the user includes bars that are recent but not so far back that they are out of the scope of where price can be. For example the last 2 years we have been in a range on the sp500 so 505 days in this setting would be more relevant than say looking back 5 years ago because price would have to move far to get there.
Show SD Bands: Select this to show the 1 standard deviation bands around the support and resistance level or unselect this to just show the support and resistance level by itself.
Features:
Besides the support and resistance levels and standard deviation bands, this indicator gives a table in the upper right hand corner to show the density of each cluster (support and resistance level) and is color coded to the cluster line on the chart. Higher density clusters mean price has been there previously more than lower density clusters and could mean a higher likelihood of a reversal when price reaches these areas.
█ WORKS CITED
Victor Sim, "Using K-means Clustering to Create Support and Resistance", 2020, towardsdatascience.com
Chris Piech, "K means", stanford.edu
█ ACKNOLWEDGMENTS
@jdehorty- Thanks for the publish template. It made organizing my thoughts and work alot easier.

Tri-State SupertrendTri-State Supertrend: Buy, Sell, Range
( Credits: Based on "Pivot Point Supertrend" by LonesomeTheBlue.)
Tri-State Supertrend incorporates a range filter into a supertrend algorithm.
So in addition to the Buy and Sell states, we now also have a Range state.
This avoids the typical "whipsaw" problem: During a range, a standard supertrend algorithm will fire Buy and Sell signals in rapid succession. These signals are all false signals as they lead to losing positions when acted on.
In this case, a tri-state supertrend will go into Range mode and stay in this mode until price exits the range and a new trend begins.
I used Pivot Point Supertrend by LonesomeTheBlue as a starting point for this script because I believe LonesomeTheBlue's version is superior to the classic Supertrend algorithm.
This indicator has two additional parameters over Pivot Point Supertrend:
A flag to turn the range filter on or off
A range size threshold in percent
With that last parameter, you can define what a range is. The best value will depend on the asset you are trading.
Also, there are two new display options.
"Show (non-) trendline for ranges" - determines whether to draw the "trendline" inside of a range. Seeing as there is no trend in a range, this is usually just visual noise.
"Show suppressed signals" - allows you to see the Buy/Sell signals that were skipped by the range filter.
How to use Tri-State Supertrend in a strategy
You can use the Buy and Sell signals to enter positions as you would with a normal supertrend. Adding stop loss, trailing stop etc. is of course encouraged and very helpful. But what to do when the Range signal appears?
I currently run a strategy on LDO based on Tri-State Supertrend which appears to be profitable. (It will quite likely be open sourced at some point, but it is not released yet.)
In that strategy, I experimented with different actions being taken when the Range state is entered:
Continue: Just keep last position open during the range
Close: Close the last position when entering range
Reversal: During the range, execute the OPPOSITE of each signal (sell on "buy", buy on "sell")
In the backtest, it transpired that "Continue" was the most profitable option for this strategy.
How ranges are detected
The mechanism is pretty simple: During each Buy or Sell trend, we record price movement, specifically, the furthest move in the trend direction that was encountered (expressed as a percentage).
When a new signal is issued, the algorithm checks whether this value (for the last trend) is below the range size set by the user. If yes, we enter Range mode.
The same logic is used to exit Range mode. This check is performed on every bar in a range, so we can enter a buy or sell as early as possible.
I found that this simple logic works astonishingly well in practice.
Pros/cons of the range filter
A range filter is an incredibly useful addition to a supertrend and will most likely boost your profits.
You will see at most one false signal at the beginning of each range (because it takes a bit of time to detect the range); after that, no more false signals will appear over the range's entire duration. So this is a huge advantage.
There is essentially only one small price you have to pay:
When a range ends, the first Buy/Sell signal you get will be delayed over the regular supertrend's signal. This is, again, because the algorithm needs some time to detect that the range has ended. If you select a range size of, say, 1%, you will essentially lose 1% of profit in each range because of this delay.
In practice, it is very likely that the benefits of a range filter outweigh its cost. Ranges can last quite some time, equating to many false signals that the range filter will completely eliminate (all except for the first one, as explained above).
You have to do your own tests though :)

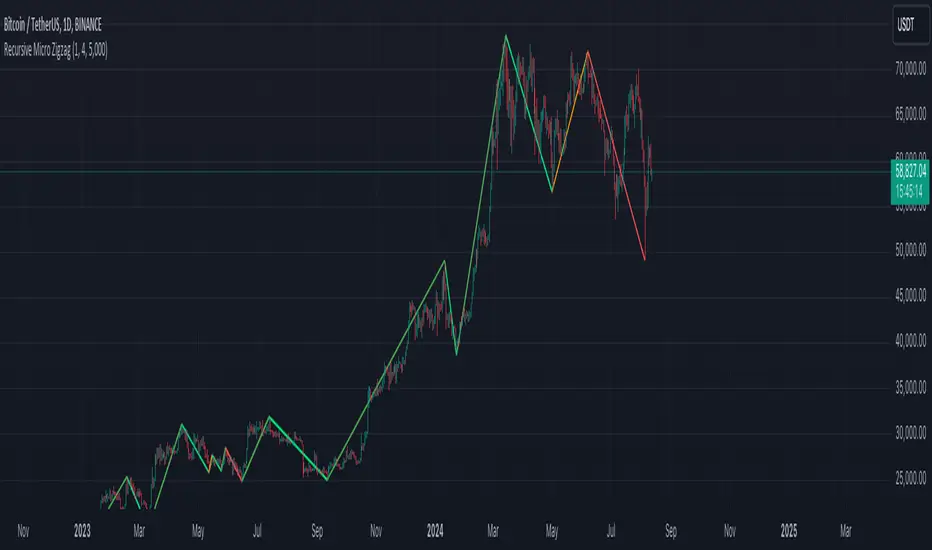
Recursive Micro Zigzag🎲 Overview
Zigzag is basic building block for any pattern recognition algorithm. This indicator is a research-oriented tool that combines the concepts of Micro Zigzag and Recursive Zigzag to facilitate a comprehensive analysis of price patterns. This indicator focuses on deriving zigzag on multiple levels in more efficient and enhanced manner in order to support enhanced pattern recognition.
The Recursive Micro Zigzag Indicator utilises the Micro Zigzag as the foundation and applies the Recursive Zigzag technique to derive higher-level zigzags. By integrating these techniques, this indicator enables researchers to analyse price patterns at multiple levels and gain a deeper understanding of market behaviour.
🎲 Concept:
Micro Zigzag Base : The indicator utilises the Micro Zigzag concept to capture detailed price movements within each candle. It allows for the visualisation of the sequential price action within the candle, aiding in pattern recognition at a micro level.
Basic implementation of micro zigzag can be found in this link - Micro-Zigzag
Recursive Zigzag Expansion : Building upon the Micro Zigzag base, the indicator applies the Recursive Zigzag concept to derive higher-level zigzags. Through recursive analysis of the Micro Zigzag's pivots, the indicator uncovers intricate patterns and trends that may not be evident in single-level zigzags.
Earlier implementations of recursive zigzag can be found here:
Recursive Zigzag
Recursive Zigzag - Trendoscope
And the libraries
rZigzag
ZigzagMethods
The major differences in this implementation are
Micro Zigzag Base - Earlier implementation made use of standard zigzag as base whereas this implementation uses Micro Zigzag as base
Not cap on Pivot depth - Earlier implementation was limited by the depth of level 0 zigzag. In this implementation, we are trying to build the recursive algorithm progressively so that there is no cap on the depth of level 0 zigzag. But, if we go for higher levels, there is chance of program timing out due to pine limitations.
These algorithms are useful in automatically spotting patterns on the chart including Harmonic Patterns, Chart Patterns, Elliot Waves and many more.
Smart Money Concepts Probability (Expo)█ Overview
The Smart Money Concept Probability (Expo) is an indicator developed to track the actions of institutional investors, commonly known as "smart money." This tool calculates the likelihood of smart money being actively engaged in buying or selling within the market, referred to as the "smart money order flow."
The indicator measures the probability of three key events: Change of Character ( CHoCH ), Shift in Market Structure ( SMS ), and Break of Structure ( BMS ). These probabilities are displayed as percentages alongside their respective levels, providing a straightforward and immediate understanding of the likelihood of smart money order flow.
Finally, the backtested results are shown in a table, which gives traders an understanding of the historical performance of the current order flow direction.
█ Calculations
The algorithm individually computes the likelihood of the events ( CHoCH , SMS , and BMS ). A positive score is assigned for events where the price successfully breaks through the level with the highest probability, and a negative score when the price fails to do so. By doing so, the algorithm determines the probability of each event occurring and calculates the total profitability derived from all the events.
█ Example
In this case, we have an 85% probability that the price will break above the upper range and make a new Break Of Structure and only a 16.36% probability that the price will break below the lower range and make a Change Of Character.
█ Settings
The Structure Period sets the pivot period to use when calculating the market structure.
The Structure Response sets how responsive the market structure should be. A low value returns a more responsive structure. A high value returns a less responsive structure.
█ How to use
This indicator is a perfect tool for anyone that wants to understand the probability of a Change of Character ( CHoCH ), Shift in Market Structure ( SMS ), and Break of Structure ( BMS )
The insights provided by this tool help traders gain an understanding of the smart money order flow direction, which can be used to determine the market trend.
█ Any Alert function call
An alert is sent when the price breaks the upper or lower range, and you can select what should be included in the alert. You can enable the following options:
Ticker ID
Timeframe
Probability percentage
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!

Breakout Probability (Expo)█ Overview
Breakout Probability is a valuable indicator that calculates the probability of a new high or low and displays it as a level with its percentage. The probability of a new high and low is backtested, and the results are shown in a table— a simple way to understand the next candle's likelihood of a new high or low. In addition, the indicator displays an additional four levels above and under the candle with the probability of hitting these levels.
The indicator helps traders to understand the likelihood of the next candle's direction, which can be used to set your trading bias.
█ Calculations
The algorithm calculates all the green and red candles separately depending on whether the previous candle was red or green and assigns scores if one or more lines were reached. The algorithm then calculates how many candles reached those levels in history and displays it as a percentage value on each line.
█ Example
In this example, the previous candlestick was green; we can see that a new high has been hit 72.82% of the time and the low only 28.29%. In this case, a new high was made.
█ Settings
Percentage Step
The space between the levels can be adjusted with a percentage step. 1% means that each level is located 1% above/under the previous one.
Disable 0.00% values
If a level got a 0% likelihood of being hit, the level is not displayed as default. Enable the option if you want to see all levels regardless of their values.
Number of Lines
Set the number of levels you want to display.
Show Statistic Panel
Enable this option if you want to display the backtest statistics for that a new high or low is made. (Only if the first levels have been reached or not)
█ Any Alert function call
An alert is sent on candle open, and you can select what should be included in the alert. You can enable the following options:
Ticker ID
Bias
Probability percentage
The first level high and low price
█ How to use
This indicator is a perfect tool for anyone that wants to understand the probability of a breakout and the likelihood that set levels are hit.
The indicator can be used for setting a stop loss based on where the price is most likely not to reach.
The indicator can help traders to set their bias based on probability. For example, look at the daily or a higher timeframe to get your trading bias, then go to a lower timeframe and look for setups in that direction.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
FATL, SATL, RFTL, & RSTL Digital Signal Filter Smoother [Loxx]FATL, SATL, RFTL, & RSTL Digital Signal Filter (DSP) Smoother is is a baseline indicator with DSP processed source inputs
What are digital indicators: distinctions from standard tools, types of filters.
To date, dozens of technical analysis indicators have been developed: trend instruments, oscillators, etc. Most of them use the method of averaging historical data, which is considered crude. But there is another group of tools - digital indicators developed on the basis of mathematical methods of spectral analysis. Their formula allows the trader to filter price noise accurately and exclude occasional surges, making the forecast more effective in comparison with conventional indicators. In this review, you will learn about their distinctions, advantages, types of digital indicators and examples of strategies based on them.
Two non-standard strategies based on digital indicators
Basic technical analysis indicators built into most platforms are based on mathematical formulas. These formulas are a reflection of market behavior in past periods. In other words, these indicators are built based on patterns that were discovered as a result of statistical analysis, which allows one to predict further trend movement to some extent. But there is also a group of indicators called digital indicators. They are developed using mathematical analysis and are an algorithmic spectral system called ATCF (Adaptive Trend & Cycles Following). In this article, I will tell you more about the components of this system, describe the differences between digital and regular indicators, and give examples of 2 strategies with indicator templates.
ATCF - Market Spectrum Analysis Method
There is a theory according to which the market is chaotic and unpredictable, i.e. it cannot be accurately analyzed. After all, no one can tell how traders will react to certain news, or whether some large investor will want to play against the market like George Soros did with the Bank of England. But there is another theory: many general market trends are logical, and have a rationale, causes and effects. The economy is undulating, which means it can be described by mathematical methods.
Digital indicators are defined as a group of algorithms for assessing the market situation, which are based exclusively on mathematical methods. They differ from standard indicators by the form of analysis display. They display certain values: price, smoothed price, volumes. Many standard indicators are built on the basis of filtering the minute significant price fluctuations with the help of moving averages and their variations. But we can hardly call the MA a good filter, because digital indicators that use spectral filters make it possible to do a more accurate calculation.
Simply put, digital indicators are technical analysis tools in which spectral filters are used to filter out price noise instead of moving averages.
The display of traditional indicators is lines, areas, and channels. Digital indicators can be displayed both in the form of lines and in digital form (a set of numbers in columns, any data in a text field, etc.). The digital display of the data is more like an additional source of statistics; for trading, a standard visual linear chart view is used.
All digital models belong to the category of spectral analysis of the market situation. In conventional technical indicators, price indications are averaged over a fixed period of time, which gives a rather rough result. The use of spectral analysis allows us to increase trading efficiency due to the fact that digital indicators use a statistical data set of past periods, which is converted into a “frequency” of the market (period of fluctuations).
Fourier theory provides the following spectral ranging of the trend duration:
low frequency range (0-4) - a reflection of a long trend of 2 months or more
medium frequency range (5-40) - the trend lasts 10-60 days, thus it is referred to as a correction
high frequency range (41-130) - price noise that lasts for several days
The ATCF algorithm is built on the basis of spectral analysis and includes a set of indicators created using digital filters. Its consists of indicators and filters:
FATL: Built on the basis of a low-frequency digital trend filter
SATL: Built on the basis of a low-frequency digital trend filter of a different order
RFTL: High frequency trend line
RSTL: Low frequency trend line
Inclucded:
4 DSP filters
Bar coloring
Keltner channels with variety ranges and smoothing functions
Bollinger bands
40 Smoothing filters
33 souce types
Variable channels

Ehlers Autocorrelation Periodogram [Loxx]Ehlers Autocorrelation Periodogram contains two versions of Ehlers Autocorrelation Periodogram Algorithm. This indicator is meant to supplement adaptive cycle indicators that myself and others have published on Trading View, will continue to publish on Trading View. These are fast-loading, low-overhead, streamlined, exact replicas of Ehlers' work without any other adjustments or inputs.
Versions:
- 2013, Cycle Analytics for Traders Advanced Technical Trading Concepts by John F. Ehlers
- 2016, TASC September, "Measuring Market Cycles"
Description
The Ehlers Autocorrelation study is a technical indicator used in the calculation of John F. Ehlers’s Autocorrelation Periodogram. Its main purpose is to eliminate noise from the price data, reduce effects of the “spectral dilation” phenomenon, and reveal dominant cycle periods. The spectral dilation has been discussed in several studies by John F. Ehlers; for more information on this, refer to sources in the "Further Reading" section.
As the first step, Autocorrelation uses Mr. Ehlers’s previous installment, Ehlers Roofing Filter, in order to enhance the signal-to-noise ratio and neutralize the spectral dilation. This filter is based on aerospace analog filters and when applied to market data, it attempts to only pass spectral components whose periods are between 10 and 48 bars.
Autocorrelation is then applied to the filtered data: as its name implies, this function correlates the data with itself a certain period back. As with other correlation techniques, the value of +1 would signify the perfect correlation and -1, the perfect anti-correlation.
Using values of Autocorrelation in Thermo Mode may help you reveal the cycle periods within which the data is best correlated (or anti-correlated) with itself. Those periods are displayed in the extreme colors (orange) while areas of intermediate colors mark periods of less useful cycles.
What is an adaptive cycle, and what is the Autocorrelation Periodogram Algorithm?
From his Ehlers' book mentioned above, page 135:
"Adaptive filters can have several different meanings. For example, Perry Kaufman’s adaptive moving average ( KAMA ) and Tushar Chande’s variable index dynamic average ( VIDYA ) adapt to changes in volatility . By definition, these filters are reactive to price changes, and therefore they close the barn door after the horse is gone.The adaptive filters discussed in this chapter are the familiar Stochastic , relative strength index ( RSI ), commodity channel index ( CCI ), and band-pass filter.The key parameter in each case is the look-back period used to calculate the indicator.This look-back period is commonly a fixed value. However, since the measured cycle period is changing, as we have seen in previous chapters, it makes sense to adapt these indicators to the measured cycle period. When tradable market cycles are observed, they tend to persist for a short while.Therefore, by tuning the indicators to the measure cycle period they are optimized for current conditions and can even have predictive characteristics.
The dominant cycle period is measured using the Autocorrelation Periodogram Algorithm. That dominant cycle dynamically sets the look-back period for the indicators. I employ my own streamlined computation for the indicators that provide smoother and easier to interpret outputs than traditional methods. Further, the indicator codes have been modified to remove the effects of spectral dilation.This basically creates a whole new set of indicators for your trading arsenal."
How to use this indicator
The point of the Ehlers Autocorrelation Periodogram Algorithm is to dynamically set a period between a minimum and a maximum period length. While I leave the exact explanation of the mechanic to Dr. Ehlers’s book, for all practical intents and purposes, in my opinion, the punchline of this method is to attempt to remove a massive source of overfitting from trading system creation–namely specifying a look-back period. SMA of 50 days? 100 days? 200 days? Well, theoretically, this algorithm takes that possibility of overfitting out of your hands. Simply, specify an upper and lower bound for your look-back, and it does the rest. In addition, this indicator tells you when its best to use adaptive cycle inputs for your other indicators.
Usage Example 1
Let's say you're using "Adaptive Qualitative Quantitative Estimation (QQE) ". This indicator has the option of adaptive cycle inputs. When the "Ehlers Autocorrelation Periodogram " shows a period of high correlation that adaptive cycle inputs work best during that period.
Usage Example 2
Check where the dominant cycle line lines, grab that output number and inject it into your other standard indicators for the length input.
Machine Learning: kNN-based StrategykNN-based Strategy (FX and Crypto)
Description:
This strategy uses a classic machine learning algorithm - k Nearest Neighbours (kNN) - to let you find a prediction for the next (tomorrow's, next month's, etc.) market move. Being an unsupervised machine learning algorithm, kNN is one of the most simple learning algorithms.
To do a prediction of the next market move, the kNN algorithm uses the historic data, collected in 3 arrays - feature1, feature2 and directions, - and finds the k-nearest
neighbours of the current indicator(s) values.
The two dimensional kNN algorithm just has a look on what has happened in the past when the two indicators had a similar level. It then looks at the k nearest neighbours,
sees their state and thus classifies the current point.
The kNN algorithm offers a framework to test all kinds of indicators easily to see if they have got any *predictive value*. One can easily add cog, wpr and others.
Note: TradingViews's playback feature helps to see this strategy in action.
Warning: Signals ARE repainting.
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours+++/Days
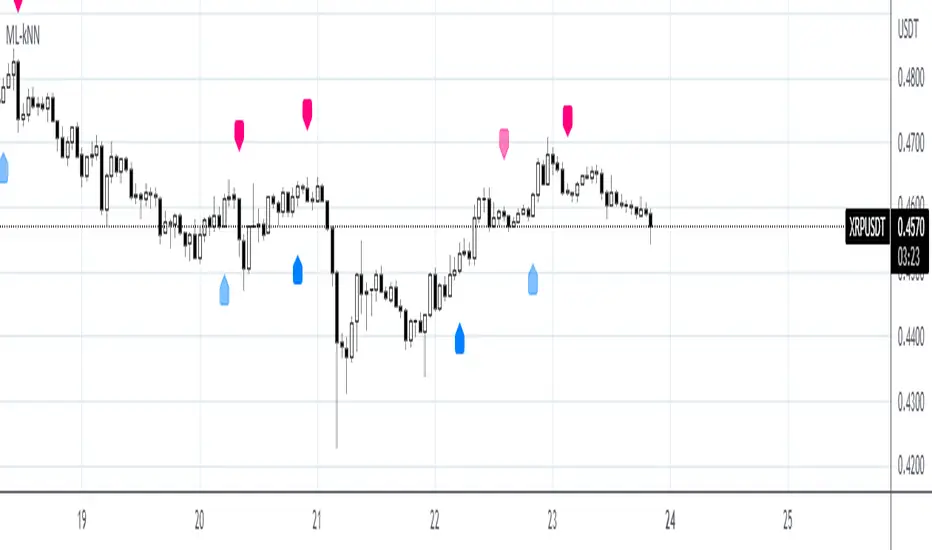
Relative Strength(RSMK) + Perks - Markos KatsanosIf you are desperately looking for a novel RSI, this isn't that. This is another lesser known novel species of indicator. Hot off the press, in multiple stunning color schemes, I present my version of "Relative Strength (RSMK)" employing PSv4.0, originally formulated by Markos Katsanos for TASC - March 2020 Traders Tips. This indicator is used to compare performance of an asset to a market index of your choosing. I included the S&P 500 index along side the Dow Jones and the NASDAQ indices selectively by an input() in "Settings". You may comparatively analyze other global market indices by adapting the code, if you are skilled enough in Pine to do so.
With this contribution to the Tradingview community, also included is MY twin algorithmic formulation of "Comparative Relative Strength" as a supplementary companion indicator. They are eerily similar, so I decided to include it. You may easily disable my algorithm within the indicator "Settings". I do hope you may find both of them useful. Configurations are displayed above in multiple scenarios that should be suitable for most traders.
As always, I have included advanced Pine programming techniques that conform to proper "Pine Etiquette". For those of you who are newcomers to Pine Script, this script may also help you understand advanced programming techniques in Pine and how they may be utilized in a most effective manner. Utilizing the "Power of Pine", I included the maximum amount of features I could surmise in an ultra small yet powerful package, being less than a 60 line implementation at initial release.
Unfortunately, there are so many Pine mastery techniques included, I don't have time to write about all of them. I will have to let you discover them for yourself, excluding the following Pine "Tricks and Tips" described next. Of notable mention with this release, I have "overwritten" the Pine built-in function ema(). You may overwrite other built-in functions too. If you weren't aware of this Pine capability, you now know! Just heed caution when doing so to ensure your replacement algorithms are 100% sound. My ema() will also accept a floating point number for the period having ultimate adjustability. Yep, you heard all of that properly. Pine is becoming more impressive than `impressive` was originally thought of...
Features List Includes:
Dark Background - Easily disabled in indicator Settings->Style for "Light" charts or with Pine commenting
AND much, much more... You have the source!
The comments section below is solely just for commenting and other remarks, ideas, compliments, etc... regarding only this indicator, not others. When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members, I may implement more ideas when they present themselves as worthy additions. As always, "Like" it if you simply just like it with a proper thumbs up, and also return to my scripts list occasionally for additional postings. Have a profitable future everyone!
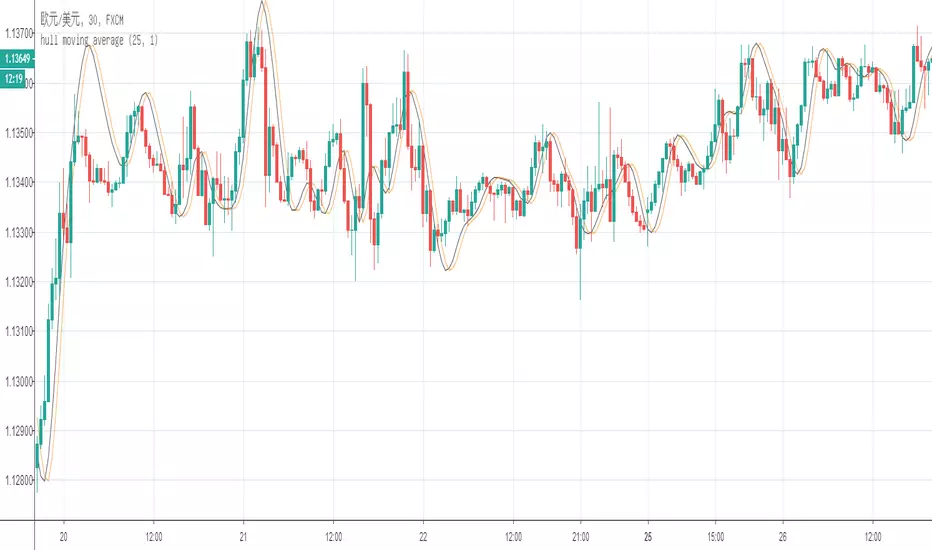
the "fasle" hull moving averageThere is a little different between my "fasle hull moving average" the "correct one".
the correct algorithm:
hma = wma((2*wma(close,n/2) - wma(close,n),sqrt(n))
the "fasle" algorithm:
=wma((2*wma(close,n/4) - wma(close,n),sqrt(n))
Amazing! Why the "fasle" describe the trend so accurate!?
MACD, backtest 2015+ only, cut in half and doubledThis is only a slight modification to the existing "MACD Strategy" strategy plugin!
found the default MACD strategy to be lacking, although impressive for its simplicity. I added "year>2014" to the IF buy/sell conditions so it will only backtest from 2015 and beyond ** .
I also had a problem with the standard MACD trading late, per se. To that end I modified the inputs for fast/slow/signal to double. Example: my defaults are 10, 21, 10 so I put 20, 42, 20 in. This has the effect of making a 30min interval the same as 1 hour at 10,21,10. So if you want to backtest at 4hr, you would set your time interval to 2hr on the main chart. This is a handy way to make shorter time periods more useful even regardless of strategy/testing, since you can view 15min with alot less noise but a better response.
Used on BTCCNY OKcoin, with the chart set at 45 min (so really 90min in the strategy) this gave me a percent profitable of 42% and a profit factor of 1.998 on 189 trades.
Personally, I like to set the length/signals to 30,63,30. Meaning you need to triple the time, it allows for much better use of shorter time periods and the backtests are remarkably profitable. (i.e. 15min chart view = 45min on script, 30min= 1.5hr on script)
** If you want more specific time periods you need to try plugging in different bar values: replace "year" with "n" and "2014" with "5500". The bars are based on unix time I believe so you will need to play around with the number for n, with n being the numbers of bars.

Alg0 Hal0 Dual MA CrossroadThe Alg0 ۞ Hal0 Dual MA Crossroad is a simple, yet high-precision trend-following indicator designed to eliminate the common pitfalls of standard Moving Average systems: lag and lack of context. By combining responsive MA algorithms with a sophisticated momentum "streak" engine, this tool provides a comprehensive view of market structure.
1. Advanced MA Algorithms
Unlike standard crossovers, this tool allows you to select from 8 different calculation methods for both the Fast and Slow lines.
ZLEMA (Zero Lag EMA): Uses a de-lagging formula to track price turns faster than a standard EMA.
DEMA (Double EMA): Provides a smoother, faster alternative to the single EMA.
HMA (Hull MA): Optimized for reducing lag while maintaining a smooth curve.
VWMA (Volume Weighted): Weights the trend by volume, showing where the "smart money" is moving.
2. Signal Engine & Momentum Streaks
The indicator looks for two primary signals:
The Crossroad: A classic crossover between the Fast and Slow MAs.
Momentum Streaks: Identifies "3-bar power moves" (3 consecutive higher closes or lower closes). These often precede or confirm a crossover, allowing for earlier entries or trend-reinforcement.
3. Smart Visuals & Label Management
ATR-Based Offsets: Labels are dynamically positioned based on current market volatility (ATR). This prevents "price clutter," ensuring labels remain visible above or below candles regardless of the asset's price.
Slope-Based Coloring: MA lines change color based on their internal slope (Bullish vs. Bearish), providing instant visual feedback on momentum shifts before a cross actually occurs.
Clean Charting: Use the Label Count Limit to prevent your chart history from becoming bogged down with old signals.
4. Integrated Intelligence Alerting
The alert system is designed for professional use. Instead of a simple "Cross Up," the webhook or popup provides a detailed report:
Trend Bias: Identifies if the current price is above/below the slow MA.
Volume Context: Automatically detects if the signal is occurring on high relative volume.
Signal Specifics: Tells you exactly which MA types crossed and if a momentum streak was detected.
How to Trade with this Indicator
The Core Setup: Look for a ZLEMA (Fast) cross over an EMA (Slow) for a balance of speed and stability.
Confirmation: Wait for a Momentum Streak alert in the direction of the crossover to confirm high-probability continuation.
Trend Riding: Stay in the trade as long as the MA Slope Color remains consistent with your direction.
Settings Glossary
Fast/Slow MA Type: Choose your calculation algorithm.
ATR Mult (Label Offset): Increase this if labels are too close to the candles.
Label Count Limit: Limits the number of labels kept on the chart to improve performance.

Timeframe-Independent Anchored VWAPAn anchored VWAP (Volume Weighted Average Price) that produces identical values (down to the tick!) across different timeframes (unlike, for example, TradingView's built-in Anchored VWAP).
Advantages
This indicator calculates identical values whether you view it on 1m, 5m, 15m, or any other timeframe within reasonable ranges. Even challenging non-integer timeframe ratios like calculating on 2m while viewing on 3m are handled perfectly. In High or Low mode, VWAP will anchor precisely at the selected candle's high/low. As usual for AVWAP, up to 3 standard deviation bands are supported.
How to Use
Setting the Anchor: When the indicator is added, select your anchor time. This is typically placed at a significant swing high/low or session open.
Source Selection: Choose whether to anchor from High, Low, or Close price.
Calculation Timeframe: Select the timeframe used for VWAP calculation.
For intraday trading (1m-1H charts): Just keep the default setting (1m)
For swing trading (4H-D charts): Use 5m or 15m calculation timeframe
For position trading (D-W charts): Use 1H calculation timeframe
Important: Lower calculation timeframes provide more precise data but may hit Pine Script's bar limit on very long timeframes
Standard Deviation Bands: Enable additional band sets as needed for your trading style.
Technical Implementation
The indicator achieves timeframe independence through the following algorithm:
Lower Timeframe Sampling: Uses Pine Script's request.security_lower_tf() to retrieve bar data at the specified calculation timeframe, regardless of the viewing timeframe. This provides consistent data resolution across all chart timeframes.
Anchor Detection: Scans the lower timeframe data to identify the exact bar containing the selected anchor price. The algorithm handles both simple cases (where anchor falls on a complete bar) and complex cases (where anchor falls within a split bar in non-integer timeframe ratios like calculating on 2m while viewing on 3m).
FIFO Buffer Management: Maintains a First-In-First-Out buffer of lower timeframe bars. On each chart bar:
Adds new lower timeframe bars to the buffer
Processes exactly one period worth of bars (matching the viewing timeframe)
Removes processed bars from the buffer
This approach ensures consistent calculation regardless of viewing timeframe.
First Bar Initialization: On the anchor bar, processes only the single anchor bar to ensure the VWAP starts exactly at the anchor price. Subsequent bars process the full period, maintaining mathematical accuracy.
VWAP Calculation: Applies the standard volume-weighted average price formula:
VWAP = Σ(Price × Volume) / Σ(Volume)
StdDev = √(Σ(Price² × Volume) / Σ(Volume) - VWAP²)
All calculations accumulate from the anchor point forward.
Visual Continuity: For edge cases where the anchor falls in an incomplete bar (e.g., calculating on 2m while viewing on 3m), displays the anchor price as a visual placeholder until the actual calculation begins on the next bar. This ensures the line always starts visually at the anchor point.

RSI Fibonacci Flow [JOAT]RSI Fibonacci Flow - Advanced Fibonacci Retracement with RSI Confluence
Introduction
RSI Fibonacci Flow is an open-source overlay indicator that combines automatic Fibonacci retracement levels with RSI momentum analysis to identify high-probability trading zones. The indicator automatically detects swing highs and lows, draws Fibonacci levels, and generates confluence signals when RSI conditions align with key Fibonacci zones.
This indicator is designed for traders who use Fibonacci retracements but want additional confirmation from momentum analysis before entering trades.
Originality and Purpose
This indicator is NOT a simple mashup of RSI and Fibonacci tools. It is an original implementation that creates a synergistic relationship between two complementary analysis methods:
Why Combine RSI with Fibonacci? Fibonacci retracements identify WHERE price might reverse, but they don't tell you WHEN. RSI provides the timing component by showing momentum exhaustion. When price reaches the Golden Zone (50%-61.8%) AND RSI shows oversold conditions, the probability of a successful bounce increases significantly.
Original Confluence Scoring System: The indicator calculates a 0-5 confluence score that weights multiple factors: Golden Zone presence (+2), entry zone presence (+1), RSI extreme alignment (+1), RSI divergence (+1), and strong RSI momentum (+1). This scoring system is original to this indicator.
Automatic Pivot Detection: Unlike manual Fibonacci tools, this indicator automatically detects swing highs and lows using a configurable pivot algorithm, then draws Fibonacci levels accordingly. The pivot detection uses a center-bar comparison method that checks if a bar's high/low is the highest/lowest within the specified depth on both sides.
Dynamic Trend Awareness: The indicator determines trend direction based on pivot sequence (last pivot was high or low) and adjusts Fibonacci orientation accordingly. In uptrends, 0% is at swing low; in downtrends, 0% is at swing high.
Each component serves a specific purpose:
Fibonacci levels identify potential reversal zones based on natural price ratios
RSI provides momentum context to filter out low-probability setups
Confluence scoring quantifies setup quality for position sizing decisions
Automatic pivot detection removes subjectivity from level placement
Core Concept: RSI-Fibonacci Confluence
The most powerful trading setups occur when multiple factors align. RSI Fibonacci Flow identifies these moments by:
Automatically detecting price pivots and drawing Fibonacci levels
Tracking which Fibonacci zone the current price occupies
Monitoring RSI for overbought/oversold conditions
Generating signals when RSI extremes coincide with key Fibonacci levels
Scoring confluence strength on a 0-5 scale
When price reaches the Golden Zone (50%-61.8%) while RSI shows oversold conditions in an uptrend, the probability of a bounce increases significantly.
Fibonacci Levels Explained
The indicator draws nine Fibonacci levels based on the most recent swing:
0% (Swing Low/High): The starting point of the move
23.6%: Shallow retracement - often seen in strong trends
38.2%: First significant support/resistance level
50%: Psychological midpoint of the move
61.8% (Golden Ratio): The most important Fibonacci level
78.6%: Deep retracement - last defense before trend failure
100% (Swing High/Low): The end point of the move
127.2% (TP1): First extension target for take profit
161.8% (TP2): Second extension target for take profit
The Golden Zone
The area between 50% and 61.8% is highlighted as the "Golden Zone" because:
It represents the optimal retracement depth for trend continuation
Institutional traders often place orders in this zone
It offers favorable risk-to-reward ratios
Price frequently bounces from this area in healthy trends
When price enters the Golden Zone, the indicator highlights it with a semi-transparent box and optional background coloring.
Pivot Detection System
The indicator uses a configurable pivot detection algorithm:
pivotDetect(float src, int len, bool isHigh) =>
int halfLen = len / 2
float centerVal = nz(src , src)
bool isPivot = true
for i = 0 to len - 1
if isHigh
if nz(src , src) > centerVal
isPivot := false
break
else
if nz(src , src) < centerVal
isPivot := false
break
isPivot ? centerVal : float(na)
This identifies swing highs and lows by checking if a bar's high/low is the highest/lowest within the specified depth on both sides.
Visual Components
1. Fibonacci Lines
Horizontal lines at each Fibonacci level:
Solid lines for major levels (0%, 50%, 61.8%, 100%)
Dashed lines for secondary levels (23.6%, 38.2%, 78.6%)
Dotted lines for extension levels (127.2%, 161.8%)
Color-coded for easy identification
Configurable line width
2. Fibonacci Labels
Price labels at each level showing:
Fibonacci percentage
Actual price at that level
Golden Zone label highlighted
TP1 and TP2 labels for targets
3. Golden Zone Box
A semi-transparent box highlighting the 50%-61.8% zone:
Gold colored border and fill
Extends from swing start to current bar (or beyond if extended)
Provides clear visual of the optimal entry zone
4. ZigZag Lines
Connecting lines between detected pivots:
Cyan for moves from low to high
Orange for moves from high to low
Helps visualize market structure
Configurable line width
5. Pivot Markers
Small labels at detected swing points:
"HH" (Higher High) at swing highs
"LL" (Lower Low) at swing lows
Helps track market structure
6. Entry Signals
BUY and SELL labels when confluence conditions are met:
BUY: RSI oversold + price in entry zone + uptrend + positive momentum
SELL: RSI overbought + price in entry zone + downtrend + negative momentum
Labels include "RSI+FIB" to indicate confluence
Confluence Scoring System
The indicator calculates a confluence score from 0 to 5:
+2 points: Price is in the Golden Zone (50%-61.8%)
+1 point: Price is in the entry zone (38.2%-61.8%)
+1 point: RSI is oversold in uptrend OR overbought in downtrend
+1 point: RSI divergence detected (bullish or bearish)
+1 point: Strong RSI momentum (change > 2 points)
Confluence ratings:
STRONG (4-5): Multiple factors align - high probability setup
MODERATE (2-3): Some factors align - proceed with caution
WEAK (0-1): Few factors align - wait for better setup
Dashboard Panel
The 10-row dashboard provides comprehensive analysis:
RSI Value: Current RSI reading (large text)
RSI State: OVERBOUGHT, OVERSOLD, BULLISH, BEARISH, or NEUTRAL
Fib Trend: UPTREND or DOWNTREND based on last pivot sequence
Price Zone: Current Fibonacci zone (e.g., "GOLDEN ZONE", "38.2% - 50%")
Price: Current close price (large text)
Confluence: Score rating with numeric value (e.g., "STRONG (4/5)")
Nearest Fib: Closest key Fibonacci level with price
TP1 (127.2%): First take profit target price
TP2 (161.8%): Second take profit target price
Input Parameters
Pivot Detection:
Pivot Depth: Bars to look back for swing detection (default: 10)
Min Deviation %: Minimum price move to confirm pivot (default: 1.0)
RSI Settings:
RSI Length: Period for RSI calculation (default: 14)
Source: Price source (default: close)
Overbought: Upper threshold (default: 70)
Oversold: Lower threshold (default: 30)
Fibonacci Display:
Show Fib Lines: Toggle Fibonacci lines (default: enabled)
Show Fib Labels: Toggle price labels (default: enabled)
Show Golden Zone Box: Toggle zone highlight (default: enabled)
Line Width: Thickness of Fibonacci lines (default: 2)
Extend Fib Lines: Extend lines into future (default: enabled)
ZigZag:
Show ZigZag: Toggle connecting lines (default: enabled)
ZigZag Width: Line thickness (default: 2)
Signals:
Show Entry Signals: Toggle BUY/SELL labels (default: enabled)
Show TP Levels: Toggle take profit in dashboard (default: enabled)
Show RSI-Fib Confluence: Toggle confluence analysis (default: enabled)
Dashboard:
Show Dashboard: Toggle information panel (default: enabled)
Position: Choose corner placement
Colors:
Bullish: Color for bullish elements (default: cyan)
Bearish: Color for bearish elements (default: orange)
Neutral: Color for neutral elements (default: gray)
Golden Zone: Color for Golden Zone highlight (default: gold)
How to Use RSI Fibonacci Flow
Identifying Entry Zones:
Wait for price to retrace to the 38.2%-61.8% zone
Check if RSI is approaching oversold (for longs) or overbought (for shorts)
Look for STRONG confluence rating in the dashboard
Enter when BUY or SELL signal appears
Setting Take Profit Targets:
TP1 at 127.2% extension for conservative target
TP2 at 161.8% extension for aggressive target
Consider scaling out at each level
Using the Price Zone:
"BELOW 23.6%" - Price hasn't retraced much; wait for deeper pullback
"23.6% - 38.2%" - Shallow retracement; strong trend continuation possible
"38.2% - 50%" - Good entry zone for trend trades
"GOLDEN ZONE" - Optimal entry zone; highest probability
"61.8% - 78.6%" - Deep retracement; trend may be weakening
"78.6% - 100%" - Very deep; trend reversal possible
"ABOVE/BELOW 100%" - Trend has likely reversed
Confluence Trading Strategy:
Only take trades with confluence score of 3 or higher
STRONG confluence (4-5) warrants larger position size
MODERATE confluence (2-3) warrants smaller position size
WEAK confluence (0-1) - wait for better setup
Alert Conditions
Ten alert conditions are available:
RSI-Fib BUY Signal: Strong bullish confluence detected
RSI-Fib SELL Signal: Strong bearish confluence detected
Price in Golden Zone: Price enters 50%-61.8% zone
New Pivot High: Swing high detected
New Pivot Low: Swing low detected
RSI Overbought: RSI crosses above overbought threshold
RSI Oversold: RSI crosses below oversold threshold
Bullish Divergence: Potential bullish RSI divergence
Bearish Divergence: Potential bearish RSI divergence
Strong Confluence: Confluence score reaches 4 or higher
Understanding Trend Direction
The indicator determines trend based on pivot sequence:
UPTREND: Last pivot was a low after a high (expecting move up)
DOWNTREND: Last pivot was a high after a low (expecting move down)
Fibonacci levels are drawn accordingly:
In uptrend: 0% at swing low, 100% at swing high
In downtrend: 0% at swing high, 100% at swing low
Bar Coloring
When confluence features are enabled:
Cyan bars on strong bullish signals
Orange bars on strong bearish signals
Gold-tinted bars when price is in Golden Zone
Best Practices
Use on 1H timeframe or higher for more reliable pivots
Adjust Pivot Depth based on timeframe (higher for longer timeframes)
Wait for price to enter Golden Zone before considering entries
Confirm RSI is in favorable territory before trading
Use extension levels (127.2%, 161.8%) for realistic profit targets
Combine with support/resistance and candlestick patterns
Higher confluence scores indicate higher probability setups
Limitations
Pivot detection has inherent lag (must wait for confirmation)
Fibonacci levels are subjective - different swings produce different levels
Works best in trending markets with clear swings
RSI can remain overbought/oversold in strong trends
Not all Golden Zone entries will be successful
The source code is open and available for review and modification.
Disclaimer
This indicator is provided for educational and informational purposes only. It is not financial advice. Trading involves substantial risk of loss. Past performance does not guarantee future results. Fibonacci levels are not guaranteed support/resistance - they are probability zones based on historical price behavior. Always conduct your own analysis and use proper risk management.
- Made with passion by officialjackofalltrades :D

Quarter Point Autopilot v2.0.0Hello traders,
I am pleased to release the Quarter Point Autopilot . This is a specialized structural framework designed to impose mathematical order on price action by synthesizing major market cycles with fractal geometric subdivisions.
Defining accurate Support and Resistance often presents a dilemma: rely on subjective, manually drawn lines that vary from trader to trader, or clutter charts with lagging moving averages. The Quarter Point Autopilot solves this by quantifying "Algorithmic Geometry." It eliminates subjectivity by projecting a universal grid based on the mathematical quarter-points that institutional algorithms utilize to execute orders.
📐 The Concept: Algorithmic Geometry
To the untrained eye, price movement can appear chaotic or random. However, professional analysis reveals that markets move in measured "Steps." Large institutions do not place orders at random numbers; they utilize specific mathematical fractions of a Major Cycle to manage liquidity.
This indicator is specifically engineered to visualize this hidden framework. By defining a "Major Cycle" (Point A and Point B), the script calculates the entire universe of the chart. It mathematically subdivides the range into Halves, Quarters, Eighths, and Sixteenths, highlighting the precise levels where price creates "Structure" and where algorithmic reactions are most likely to occur.
⚙️ The Autopilot Logic: Infinite Scroll
In previous iterations of quarter-theory tools, traders were forced to manually redraw grids as price expanded into new territories.
This version introduces the "Autopilot" engine ( current_base logic ). The script dynamically detects which "Block" price is currently trading within and automatically projects the grid forward and backward in real-time. Whether price rallies 1,000 points or drops 500, the mathematical subdivisions snap to the correct integer block immediately, ensuring you never trade without context.
📊 Fractal Hierarchy
Not all levels are created equal. The indicator uses a visual hierarchy to help you distinguish the strength of a level at a glance:
Major Cycle: The "Hard Deck" boundaries of the range (0% / 100%).
Half-Major: The Equilibrium of the cycle (50%).
Large Quarters: The standard deviation points (25% / 75%).
Mid & Small Quarters: The granular detail (Eighths and Sixteenths) for precision entries.
User Guide:
Simply input two "Major Cycle Points" (a significant High and Low) in the settings. The script calculates the "Step Size" and handles the rest, projecting the grid relative to current price action.
Settings Include:
Calculation Group: Set your Point A and Point B to define the grid size.
Visual Group: Toggle the upper/lower buffers and customize the lookback/lookforward lengths to keep your chart clean.
Label Group: Choose to see Level Names, Prices, or both.

Moon Phases & Declinations - Chronos Capital [BETA]High-Precision Lunar Cycles: Moon Phases & Declinations (Swiss Ephemeris)
Overview
This indicator provides institutional-grade astronomical data directly on your chart. Unlike standard scripts that use basic sine-wave approximations, this tool implements the **Swiss Ephemeris algorithm**, the gold standard for high-precision celestial calculations.
By tracking the Moon’s phases and its **Maximum/Minimum Declinations**, traders can identify potential "turning points" or "energy shifts" in market volatility often associated with lunar cycles.
---
Key Features
Ultra-High Precision: Calculations are accurate to within *seconds* of time, ensuring that the visual plot aligns perfectly with astronomical reality.
Moon Phase Tracking: Distinct markers for New Moon, Full Moon, and Quarters.
Lunar Declination Peaks: Automatically identifies when the moon reaches its *Maximum North* and *Maximum South* points (Lunar Extremes).
Customizable Visuals: Toggle between background highlights, vertical lines, or plot signals to suit your trading style.
---
Technical Accuracy
This script is built using a ported version of the Swiss Ephemeris
Positional Accuracy: Within 0.1 arcseconds.
Time Accuracy: Within **~1-2 seconds** of official JPL data.
Algorithm: Integration of the *ELP2000-85* lunar theory for maximum reliability over decades of historical data.
---
### **How to Use**
1. **Reversal Zones:** Watch for the Moon’s *Max/Min Declination* points, which often coincide with local tops or bottoms in trending markets.
2. **Volatility Shifts:** Use the *New Moon* and *Full Moon* markers to anticipate periods of increased or decreased market liquidity and volume.
3. **Confluence:** Best used in combination with your existing price action or momentum indicators to add a "time-based" filter to your entries.
*Disclaimer: This tool is for educational and analytical purposes only. Lunar cycles are a study of time-based correlation, not a guaranteed financial signal.*

Neosha Concept V4 (NY Time)
Imagine the financial market as a huge ocean. Millions of traders throw orders into it every second. But beneath all the noise, there is a powerful current that quietly controls where the waves move. That current is not a person, not a trader, and not random—it is an algorithm.
This algorithm is called the Interbank Price Delivery Algorithm (IPDA).
Think of it as the “navigation system” that guides price through the market.
IPDA has one job:
to move prices in a way that keeps the market efficient and liquid.
To do this, it constantly looks for two things:
1. Where liquidity is hiding
Liquidity is usually found above highs and below lows—where traders place stop losses. The algorithm moves price there first to collect that liquidity.
2. Where price became unbalanced
Sometimes price moves too fast and creates gaps or imbalances. IPDA returns to those areas later to “fix” the missing orders.
Once you start looking at the charts with this idea in mind, everything makes more sense:
Why price suddenly spikes above a high and crashes down
Why big moves leave gaps that price later fills
Why the market reverses right after taking stops
Why trends begin only after certain levels are hit
These are not accidents.
They are the algorithm doing its job.
Price moves in a repeating cycle:
Gather liquidity
Make a strong move (displacement)
Return to fix inefficiency
Deliver to the next target
Most beginners only see the candles.
But once you understand IPDA, you see the intention behind the candles.
Instead of guessing where price might go, you begin to understand why it moves there.
And once you understand the “why,” your trading becomes clearer, calmer, and far more accurate.
