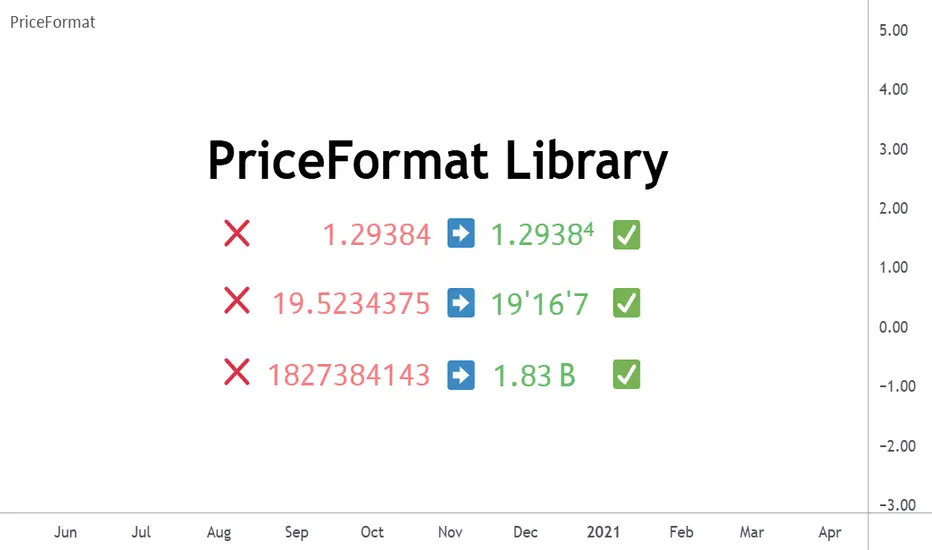
PriceFormatLibrary for automatically converting price values to formatted strings
matching the same format that TradingView uses to display open/high/low/close prices on the chart.
█ OVERVIEW
This library is intended for Pine Coders who are authors of scripts that display numbers onto a user's charts. Typically, 𝚜𝚝𝚛.𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐() would be used to convert a number into a string which can be displayed in a label / box / table, but this only works well for values that are formatted as a simple decimal number. The purpose of this library is to provide an easy way to create a formatted string for values which use other types of formats besides the decimal format.
The main functions exported by this library are:
𝚏𝚘𝚛𝚖𝚊𝚝𝙿𝚛𝚒𝚌𝚎() - creates a formatted string from a price value
𝚖𝚎𝚊𝚜𝚞𝚛𝚎𝙿𝚛𝚒𝚌𝚎𝙲𝚑𝚊𝚗𝚐𝚎() - creates a formatted string from the distance between two prices
𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐() - an alternative to the built-in 𝚜𝚝𝚛.𝚝𝚘𝚜𝚝𝚛𝚒𝚗𝚐(𝚟𝚊𝚕𝚞𝚎, 𝚏𝚘𝚛𝚖𝚊𝚝)
This library also exports some auxiliary functions which are used under the hood of the previously mentioned functions, but can also be useful to Pine Coders that need fine-tuned control for customized formatting of numeric values:
Functions that determine information about the current chart:
𝚒𝚜𝙵𝚛𝚊𝚌𝚝𝚒𝚘𝚗𝚊𝚕𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝚅𝚘𝚕𝚞𝚖𝚎𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙿𝚎𝚛𝚌𝚎𝚗𝚝𝚊𝚐𝚎𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙳𝚎𝚌𝚒𝚖𝚊𝚕𝙵𝚘𝚛𝚖𝚊𝚝(), 𝚒𝚜𝙿𝚒𝚙𝚜𝙵𝚘𝚛𝚖𝚊𝚝()
Functions that convert a 𝚏𝚕𝚘𝚊𝚝 value to a formatted string:
𝚊𝚜𝙳𝚎𝚌𝚒𝚖𝚊𝚕(), 𝚊𝚜𝙿𝚒𝚙𝚜(), 𝚊𝚜𝙵𝚛𝚊𝚌𝚝𝚒𝚘𝚗𝚊𝚕(), 𝚊𝚜𝚅𝚘𝚕𝚞𝚖𝚎()
█ EXAMPLES
• Simple Example
This example shows the simplest way to utilize this library.
//@version=6
indicator("Simple Example")
import n00btraders/PriceFormat/1
var table t = table.new(position.middle_right, 2, 1, bgcolor = color.new(color.blue, 90), force_overlay = true)
if barstate.isfirst
table.cell(t, 0, 0, "Current Price: ", text_color = color.black, text_size = 40)
table.cell(t, 1, 0, text_color = color.blue, text_size = 40)
if barstate.islast
string lastPrice = close.formatPrice() // Simple, easy way to format price
table.cell_set_text(t, 1, 0, lastPrice)
• Complex Example
This example calls all of the main functions and uses their optional arguments.
//@version=6
indicator("Complex Example")
import n00btraders/PriceFormat/1
// Enum values that can be used as optional arguments
precision = input.enum(PriceFormat.Precision.DEFAULT)
language = input.enum(PriceFormat.Language.ENGLISH)
// Main library functions used to create formatted strings
string formattedOpen = open.formatPrice(precision, language, allowPips = true)
string rawOpenPrice = PriceFormat.tostring(open, format.price)
string formattedClose = close.formatPrice(precision, language, allowPips = true)
string rawClosePrice = PriceFormat.tostring(close, format.price)
= PriceFormat.measurePriceChange(open, close, precision, language, allowPips = true)
// Labels to display formatted values on chart
string prices = str.format("Open: {0} ({1}) Close: {2} ({3})", formattedOpen, rawOpenPrice, formattedClose, rawClosePrice)
string change = str.format("Change (close - open): {0} / {1}", distance, ticks)
label.new(chart.point.now(high), prices, yloc = yloc.abovebar, textalign = text.align_left, force_overlay = true)
label.new(chart.point.now(low), change, yloc = yloc.belowbar, style = label.style_label_up, force_overlay = true)
█ NOTES
• Function Descriptions
The library source code uses Markdown for the exported functions. Hover over a function/method call in the Pine Editor to display formatted, detailed information about the function/method.
• Precision Settings
The Precision option in the chart settings can change the format of how prices are displayed on the chart. Since the user's selected choice cannot be known through any Pine built-in variable, this library provides a 𝙿𝚛𝚎𝚌𝚒𝚜𝚒𝚘𝚗 enum that can be used as an optional script input for the user to specify their selected choice.
• Language Settings
The Language option in the user menu can change the decimal/grouping separators in the prices that are displayed on the chart. Since the user's selected choice cannot be known through any Pine built-in variable, this library provides a 𝙻𝚊𝚗𝚐𝚞𝚊𝚐𝚎 enum that can be used as an optional script input for the user to specify their selected choice.
█ EXPORTED FUNCTIONS
method formatPrice(price, precision, language, allowPips)
Formats a price value to match how it would be displayed on the user's current chart.
Namespace types: series float, simple float, input float, const float
Parameters:
price (float) : The value to format.
precision (series Precision) : A Precision.* enum value.
language (series Language) : A Language.* enum value.
allowPips (simple bool) : Whether to allow decimal numbers to display as pips.
Returns: Automatically formatted price string.
measurePriceChange(startPrice, endPrice, precision, language, allowPips)
Measures a change in price in terms of both distance and ticks.
Parameters:
startPrice (float) : The starting price.
endPrice (float) : The ending price.
precision (series Precision) : A Precision.* enum value.
language (series Language) : A Language.* enum value.
allowPips (simple bool) : Whether to allow decimal numbers to display as pips.
Returns: A tuple of formatted strings: .
method tostring(value, format)
Alternative to the Pine `str.tostring(value, format)` built-in function.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : (series float) The value to format.
format (string) : (series string) The format string.
Returns: String in the specified format.
isFractionalFormat()
Determines if the default behavior of the chart's price scale is to use a fractional format.
Returns: True if the chart can display prices in fractional format.
isVolumeFormat()
Determines if the default behavior of the chart's price scale is to display prices as volume.
Returns: True if the chart can display prices as volume.
isPercentageFormat()
Determines if the default behavior of the chart's price scale is to display percentages.
Returns: True if the chart can display prices as percentages.
isDecimalFormat()
Determines if the default behavior of the chart's price scale is to use a decimal format.
Returns: True if the chart can display prices in decimal format.
isPipsFormat()
Determines if the current symbol's prices can be displayed as pips.
Returns: True if the chart can display prices as pips.
method asDecimal(value, precision, minTick, decimalSeparator, groupingSeparator, eNotation)
Converts a number to a string in decimal format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
precision (int) : Number of decimal places.
minTick (float) : Minimum tick size.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
eNotation (bool) : Whether the result should use E notation.
Returns: String in decimal format.
method asPips(value, priceScale, minMove, minMove2, decimalSeparator, groupingSeparator)
Converts a number to a string in decimal format with the last digit replaced by a superscript.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
priceScale (int) : Price scale.
minMove (int) : Min move.
minMove2 (int) : Min move 2.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
Returns: String in decimal format with an emphasis on the pip value.
method asFractional(value, priceScale, minMove, minMove2, fractionalSeparator1, fractionalSeparator2)
Converts a number to a string in fractional format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
priceScale (int) : Price scale.
minMove (int) : Min move.
minMove2 (int) : Min move 2.
fractionalSeparator1 (string) : The primary fractional separator.
fractionalSeparator2 (string) : The secondary fractional separator.
Returns: String in fractional format.
method asVolume(value, precision, minTick, decimalSeparator, groupingSeparator, spacing)
Converts a number to a string in volume format.
Namespace types: series float, simple float, input float, const float
Parameters:
value (float) : The value to format.
precision (int) : Maximum number of decimal places.
minTick (float) : Minimum tick size.
decimalSeparator (string) : The decimal separator.
groupingSeparator (string) : The thousands separator, aka digit group separator.
spacing (string) : The whitespace separator.
Returns: String in volume format.
אינדיקטורים ואסטרטגיות
LibVPrfLibrary "LibVPrf"
This library provides an object-oriented framework for volume
profile analysis in Pine Script®. It is built around the `VProf`
User-Defined Type (UDT), which encapsulates all data, settings,
and statistical metrics for a single profile, enabling stateful
analysis with on-demand calculations.
Key Features:
1. **Object-Oriented Design (UDT):** The library is built around
the `VProf` UDT. This object encapsulates all profile data
and provides methods for its full lifecycle management,
including creation, cloning, clearing, and merging of profiles.
2. **Volume Allocation (`AllotMode`):** Offers two methods for
allocating a bar's volume:
- **Classic:** Assigns the entire bar's volume to the close
price bucket.
- **PDF:** Distributes volume across the bar's range using a
statistical price distribution model from the `LibBrSt` library.
3. **Buy/Sell Volume Splitting (`SplitMode`):** Provides methods
for classifying volume into buying and selling pressure:
- **Classic:** Classifies volume based on the bar's color (Close vs. Open).
- **Dynamic:** A specific model that analyzes candle structure
(body vs. wicks) and a short-term trend factor to
estimate the buy/sell share at each price level.
4. **Statistical Analysis (On-Demand):** Offers a suite of
statistical metrics calculated using a "Lazy Evaluation"
pattern (computed only when requested via `get...` methods):
- **Central Tendency:** Point of Control (POC), VWAP, and Median.
- **Dispersion:** Value Area (VA) and Population Standard Deviation.
- **Shape:** Skewness and Excess Kurtosis.
- **Delta:** Cumulative Volume Delta, including its
historical high/low watermarks.
5. **Structural Analysis:** Includes a parameter-free method
(`getSegments`) to decompose a profile into its fundamental
unimodal segments, allowing for modality detection (e.g.,
identifying bimodal profiles).
6. **Dynamic Profile Management:**
- **Auto-Fitting:** Profiles set to `dynamic = true` will
automatically expand their price range to fit new data.
- **Manipulation:** The resolution, price range, and Value Area
of a dynamic profile can be changed at any time. This
triggers a resampling process that uses a **linear
interpolation model** to re-bucket existing volume.
- **Assumption:** Non-dynamic profiles are fixed and will throw
a `runtime.error` if `addBar` is called with data
outside their initial range.
7. **Bucket-Level Access:** Provides getter methods for direct
iteration and analysis of the raw buy/sell volume and price
boundaries of each individual price bucket.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
create(buckets, rangeUp, rangeLo, dynamic, valueArea, allot, estimator, cdfSteps, split, trendLen)
Construct a new `VProf` object with fixed bucket count & range.
Parameters:
buckets (int) : series int number of price buckets ≥ 1
rangeUp (float) : series float upper price bound (absolute)
rangeLo (float) : series float lower price bound (absolute)
dynamic (bool) : series bool Flag for dynamic adaption of profile ranges
valueArea (int) : series int Percentage of total volume to include in the Value Area (1..100)
allot (series AllotMode) : series AllotMode Allocation mode `classic` or `pdf` (default `classic`)
estimator (series PriceEst enum from AustrianTradingMachine/LibBrSt/1) : series LibBrSt.PriceEst PDF model when `model == PDF`. (deflault = 'uniform')
cdfSteps (int) : series int even #sub-intervals for Simpson rule (default 20)
split (series SplitMode) : series SplitMode Buy/Sell determination (default `classic`)
trendLen (int) : series int Look‑back bars for trend factor (default 3)
Returns: VProf freshly initialised profile
method clone(self)
Create a deep copy of the volume profile.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object to copy
Returns: VProf A new, independent copy of the profile
method clear(self)
Reset all bucket tallies while keeping configuration intact.
Namespace types: VProf
Parameters:
self (VProf) : VProf profile object
Returns: VProf cleared profile (chaining)
method merge(self, srcABuy, srcASell, srcRangeUp, srcRangeLo, srcCvd, srcCvdHi, srcCvdLo)
Merges volume data from a source profile into the current profile.
If resizing is needed, it performs a high-fidelity re-bucketing of existing
volume using a linear interpolation model inferred from neighboring buckets,
preventing aliasing artifacts and ensuring accurate volume preservation.
Namespace types: VProf
Parameters:
self (VProf) : VProf The target profile object to merge into.
srcABuy (array) : array The source profile's buy volume bucket array.
srcASell (array) : array The source profile's sell volume bucket array.
srcRangeUp (float) : series float The upper price bound of the source profile.
srcRangeLo (float) : series float The lower price bound of the source profile.
srcCvd (float) : series float The final Cumulative Volume Delta (CVD) value of the source profile.
srcCvdHi (float) : series float The historical high-water mark of the CVD from the source profile.
srcCvdLo (float) : series float The historical low-water mark of the CVD from the source profile.
Returns: VProf `self` (chaining), now containing the merged data.
method addBar(self, offset)
Add current bar’s volume to the profile (call once per realtime bar).
classic mode: allocates all volume to the close bucket and classifies
by `close >= open`. PDF mode: distributes volume across buckets by the
estimator’s CDF mass. For `split = dynamic`, the buy/sell share per
price is computed via context-driven piecewise s(u).
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
offset (int) : series int To offset the calculated bar
Returns: VProf `self` (method chaining)
method setBuckets(self, buckets)
Sets the number of buckets for the volume profile.
Behavior depends on the `isDynamic` flag.
- If `dynamic = true`: Works on filled profiles by re-bucketing to a new resolution.
- If `dynamic = false`: Only works on empty profiles to prevent accidental changes.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
buckets (int) : series int The new number of buckets
Returns: VProf `self` (chaining)
method setRanges(self, rangeUp, rangeLo)
Sets the price range for the volume profile.
Behavior depends on the `dynamic` flag.
- If `dynamic = true`: Works on filled profiles by re-bucketing existing volume.
- If `dynamic = false`: Only works on empty profiles to prevent accidental changes.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
rangeUp (float) : series float The new upper price bound
rangeLo (float) : series float The new lower price bound
Returns: VProf `self` (chaining)
method setValueArea(self, valueArea)
Set the percentage of volume for the Value Area. If the value
changes, the profile is finalized again.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
valueArea (int) : series int The new Value Area percentage (0..100)
Returns: VProf `self` (chaining)
method getBktBuyVol(self, idx)
Get Buy volume of a bucket.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
idx (int) : series int Bucket index
Returns: series float Buy volume ≥ 0
method getBktSellVol(self, idx)
Get Sell volume of a bucket.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
idx (int) : series int Bucket index
Returns: series float Sell volume ≥ 0
method getBktBnds(self, idx)
Get Bounds of a bucket.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
idx (int) : series int Bucket index
Returns:
up series float The upper price bound of the bucket.
lo series float The lower price bound of the bucket.
method getPoc(self)
Get POC information.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
Returns:
pocIndex series int The index of the Point of Control (POC) bucket.
pocPrice. series float The mid-price of the Point of Control (POC) bucket.
method getVA(self)
Get Value Area (VA) information.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object
Returns:
vaUpIndex series int The index of the upper bound bucket of the Value Area.
vaUpPrice series float The upper price bound of the Value Area.
vaLoIndex series int The index of the lower bound bucket of the Value Area.
vaLoPrice series float The lower price bound of the Value Area.
method getMedian(self)
Get the profile's median price and its bucket index. Calculates the value on-demand if stale.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns:
medianIndex series int The index of the bucket containing the Median.
medianPrice series float The Median price of the profile.
method getVwap(self)
Get the profile's VWAP and its bucket index. Calculates the value on-demand if stale.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns:
vwapIndex series int The index of the bucket containing the VWAP.
vwapPrice series float The Volume Weighted Average Price of the profile.
method getStdDev(self)
Get the profile's volume-weighted standard deviation. Calculates the value on-demand if stale.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns: series float The Standard deviation of the profile.
method getSkewness(self)
Get the profile's skewness. Calculates the value on-demand if stale.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns: series float The Skewness of the profile.
method getKurtosis(self)
Get the profile's excess kurtosis. Calculates the value on-demand if stale.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns: series float The Kurtosis of the profile.
method getSegments(self)
Get the profile's fundamental unimodal segments. Calculates on-demand if stale.
Uses a parameter-free, pivot-based recursive algorithm.
Namespace types: VProf
Parameters:
self (VProf) : VProf The profile object.
Returns: matrix A 2-column matrix where each row is an pair.
method getCvd(self)
Cumulative Volume Delta (CVD) like metric over all buckets.
Namespace types: VProf
Parameters:
self (VProf) : VProf Profile object.
Returns:
cvd series float The final Cumulative Volume Delta (Total Buy Vol - Total Sell Vol).
cvdHi series float The running high-water mark of the CVD as volume was added.
cvdLo series float The running low-water mark of the CVD as volume was added.
VProf
VProf Bucketed Buy/Sell volume profile plus meta information.
Fields:
buckets (series int) : int Number of price buckets (granularity ≥1)
rangeUp (series float) : float Upper price range (absolute)
rangeLo (series float) : float Lower price range (absolute)
dynamic (series bool) : bool Flag for dynamic adaption of profile ranges
valueArea (series int) : int Percentage of total volume to include in the Value Area (1..100)
allot (series AllotMode) : AllotMode Allocation mode `classic` or `pdf`
estimator (series PriceEst enum from AustrianTradingMachine/LibBrSt/1) : LibBrSt.PriceEst Price density model when `model == PDF`
cdfSteps (series int) : int Simpson integration resolution (even ≥2)
split (series SplitMode) : SplitMode Buy/Sell split strategy per bar
trendLen (series int) : int Look‑back length for trend factor (≥1)
maxBkt (series int) : int User-defined number of buckets (unclamped)
aBuy (array) : array Buy volume per bucket
aSell (array) : array Sell volume per bucket
cvd (series float) : float Final Cumulative Volume Delta (Total Buy Vol - Total Sell Vol).
cvdHi (series float) : float Running high-water mark of the CVD as volume was added.
cvdLo (series float) : float Running low-water mark of the CVD as volume was added.
poc (series int) : int Index of max‑volume bucket (POC). Is `na` until calculated.
vaUp (series int) : int Index of upper Value‑Area bound. Is `na` until calculated.
vaLo (series int) : int Index of lower value‑Area bound. Is `na` until calculated.
median (series float) : float Median price of the volume distribution. Is `na` until calculated.
vwap (series float) : float Profile VWAP (Volume Weighted Average Price). Is `na` until calculated.
stdDev (series float) : float Standard Deviation of volume around the VWAP. Is `na` until calculated.
skewness (series float) : float Skewness of the volume distribution. Is `na` until calculated.
kurtosis (series float) : float Excess Kurtosis of the volume distribution. Is `na` until calculated.
segments (matrix) : matrix A 2-column matrix where each row is an pair. Is `na` until calculated.

LibBrStLibrary "LibBrSt"
This is a library for quantitative analysis, designed to estimate
the statistical properties of price movements *within* a single
OHLC bar, without requiring access to tick data. It provides a
suite of estimators based on various statistical and econometric
models, allowing for analysis of intra-bar volatility and
price distribution.
Key Capabilities:
1. **Price Distribution Models (`PriceEst`):** Provides a selection
of estimators that model intra-bar price action as a probability
distribution over the range. This allows for the
calculation of the intra-bar mean (`priceMean`) and standard
deviation (`priceStdDev`) in absolute price units. Models include:
- **Symmetric Models:** `uniform`, `triangular`, `arcsine`,
`betaSym`, and `t4Sym` (Student-t with fat tails).
- **Skewed Models:** `betaSkew` and `t4Skew`, which adjust
their shape based on the Open/Close position.
- **Model Assumptions:** The skewed models rely on specific
internal constants. `betaSkew` uses a fixed concentration
parameter (`BETA_SKEW_CONCENTRATION = 4.0`), and `t4Sym`/`t4Skew`
use a heuristic scaling factor (`T4_SHAPE_FACTOR`)
to map the distribution.
2. **Econometric Log-Return Estimators (`LogEst`):** Includes a set of
econometric estimators for calculating the volatility (`logStdDev`)
and drift (`logMean`) of logarithmic returns within a single bar.
These are unit-less measures. Models include:
- **Parkinson (1980):** A High-Low range estimator.
- **Garman-Klass (1980):** An OHLC-based estimator.
- **Rogers-Satchell (1991):** An OHLC estimator that accounts
for non-zero drift.
3. **Distribution Analysis (PDF/CDF):** Provides functions to work
with the Probability Density Function (`pricePdf`) and
Cumulative Distribution Function (`priceCdf`) of the
chosen price model.
- **Note on `priceCdf`:** This function uses analytical (exact)
calculations for the `uniform`, `triangular`, and `arcsine`
models. For all other models (e.g., `betaSkew`, `t4Skew`),
it uses **numerical integration (Simpson's rule)** as
an approximation of the cumulative probability.
4. **Mathematical Functions:** The library's Beta distribution
models (`betaSym`, `betaSkew`) are supported by an internal
implementation of the natural log-gamma function, which is
based on the Lanczos approximation.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
priceStdDev(estimator, offset)
Estimates **σ̂** (standard deviation) *in price units* for the current
bar, according to the chosen `PriceEst` distribution assumption.
Parameters:
estimator (series PriceEst) : series PriceEst Distribution assumption (see enum).
offset (int) : series int To offset the calculated bar
Returns: series float σ̂ ≥ 0 ; `na` if undefined (e.g. zero range).
priceMean(estimator, offset)
Estimates **μ̂** (mean price) for the chosen `PriceEst` within the
current bar.
Parameters:
estimator (series PriceEst) : series PriceEst Distribution assumption (see enum).
offset (int) : series int To offset the calculated bar
Returns: series float μ̂ in price units.
pricePdf(estimator, price, offset)
Probability-density under the chosen `PriceEst` model.
**Returns 0** when `p` is outside the current bar’s .
Parameters:
estimator (series PriceEst) : series PriceEst Distribution assumption (see enum).
price (float) : series float Price level to evaluate.
offset (int) : series int To offset the calculated bar
Returns: series float Density value.
priceCdf(estimator, upper, lower, steps, offset)
Cumulative probability **between** `upper` and `lower` under
the chosen `PriceEst` model. Outside-bar regions contribute zero.
Uses a fast, analytical calculation for Uniform, Triangular, and
Arcsine distributions, and defaults to numerical integration
(Simpson's rule) for more complex models.
Parameters:
estimator (series PriceEst) : series PriceEst Distribution assumption (see enum).
upper (float) : series float Upper Integration Boundary.
lower (float) : series float Lower Integration Boundary.
steps (int) : series int # of sub-intervals for numerical integration (if used).
offset (int) : series int To offset the calculated bar.
Returns: series float Probability mass ∈ .
logStdDev(estimator, offset)
Estimates **σ̂** (standard deviation) of *log-returns* for the current bar.
Parameters:
estimator (series LogEst) : series LogEst Distribution assumption (see enum).
offset (int) : series int To offset the calculated bar
Returns: series float σ̂ (unit-less); `na` if undefined.
logMean(estimator, offset)
Estimates μ̂ (mean log-return / drift) for the chosen `LogEst`.
The returned value is consistent with the assumptions of the
selected volatility estimator.
Parameters:
estimator (series LogEst) : series LogEst Distribution assumption (see enum).
offset (int) : series int To offset the calculated bar
Returns: series float μ̂ (unit-less log-return).

LibPvotLibrary "LibPvot"
This is a library for advanced technical analysis, specializing
in two core areas: the detection of price-oscillator
divergences and the analysis of market structure. It provides
a back-end engine for signal detection and a toolkit for
indicator plotting.
Key Features:
1. **Complete Divergence Suite (Class A, B, C):** The engine detects
all three major types of divergences, providing a full spectrum of
analytical signals:
- **Regular (A):** For potential trend reversals.
- **Hidden (B):** For potential trend continuations.
- **Exaggerated (C):** For identifying weakness at double tops/bottoms.
2. **Advanced Signal Filtering:** The detection logic uses a
percentage-based price tolerance (`prcTol`). This feature
enables the practical detection of Exaggerated divergences
(which rarely occur at the exact same price) and creates a
"dead zone" to filter insignificant noise from triggering
Regular divergences.
3. **Pivot Synchronization:** A bar tolerance (`barTol`) is used
to reliably match price and oscillator pivots that do not
align perfectly on the same bar, preventing missed signals.
4. **Signal Invalidation Logic:** Features two built-in invalidation
rules:
- An optional `invalidate` parameter automatically terminates
active divergences if the price or the oscillator breaks
the level of the confirming pivot.
- The engine also discards 'half-pivots' (e.g., a price pivot)
if a corresponding oscillator pivot does not appear within
the `barTol` window.
5. **Stateful Plotting Helpers:** Provides helper functions
(`bullDivPos` and `bearDivPos`) that abstract away the
state management issues of visualizing persistent signals.
They generate gap-free, accurately anchored data series
ready to be used in `plotshape` functions, simplifying
indicator-side code.
6. **Rich Data Output:** The core detection functions (`bullDiv`, `bearDiv`)
return a comprehensive 9-field data tuple. This includes the
boolean flags for each divergence type and the precise
coordinates (price, oscillator value, bar index) of both the
starting and the confirming pivots.
7. **Market Structure & Trend Analysis:** Includes a
`marketStructure` function to automatically identify pivot
highs/lows, classify their relationship (HH, LH, LL, HL),
detect structure breaks, and determine the current trend
state (Up, Down, Neutral) based on pivot sequences.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
bullDiv(priceSrc, oscSrc, leftLen, rightLen, depth, barTol, prcTol, persist, invalidate)
Detects bullish divergences (Regular, Hidden, Exaggerated) based on pivot lows.
Parameters:
priceSrc (float) : series float Price series to check for pivots (e.g., `low`).
oscSrc (float) : series float Oscillator series to check for pivots.
leftLen (int) : series int Number of bars to the left of a pivot (default 5).
rightLen (int) : series int Number of bars to the right of a pivot (default 5).
depth (int) : series int Maximum number of stored pivot pairs to check against (default 2).
barTol (int) : series int Maximum bar distance allowed between the price pivot and the oscillator pivot (default 3).
prcTol (float) : series float The percentage tolerance for comparing pivot prices. Used to detect Exaggerated
divergences and filter out market noise (default 0.05%).
persist (bool) : series bool If `true` (default), the divergence flag stays active for the entire duration of the signal.
If `false`, it returns a single-bar pulse on detection.
invalidate (bool) : series bool If `true` (default), terminates an active divergence if price or oscillator break
below the confirming pivot low.
Returns: A tuple containing comprehensive data for a detected bullish divergence.
regBull series bool `true` if a Regular bullish divergence (Class A) is active.
hidBull series bool `true` if a Hidden bullish divergence (Class B) is active.
exgBull series bool `true` if an Exaggerated bullish divergence (Class C) is active.
initPivotPrc series float Price value of the initial (older) pivot low.
initPivotOsz series float Oscillator value of the initial pivot low.
initPivotBar series int Bar index of the initial pivot low.
lastPivotPrc series float Price value of the last (confirming) pivot low.
lastPivotOsz series float Oscillator value of the last pivot low.
lastPivotBar series int Bar index of the last pivot low.
bearDiv(priceSrc, oscSrc, leftLen, rightLen, depth, barTol, prcTol, persist, invalidate)
Detects bearish divergences (Regular, Hidden, Exaggerated) based on pivot highs.
Parameters:
priceSrc (float) : series float Price series to check for pivots (e.g., `high`).
oscSrc (float) : series float Oscillator series to check for pivots.
leftLen (int) : series int Number of bars to the left of a pivot (default 5).
rightLen (int) : series int Number of bars to the right of a pivot (default 5).
depth (int) : series int Maximum number of stored pivot pairs to check against (default 2).
barTol (int) : series int Maximum bar distance allowed between the price pivot and the oscillator pivot (default 3).
prcTol (float) : series float The percentage tolerance for comparing pivot prices. Used to detect Exaggerated
divergences and filter out market noise (default 0.05%).
persist (bool) : series bool If `true` (default), the divergence flag stays active for the entire duration of the signal.
If `false`, it returns a single-bar pulse on detection.
invalidate (bool) : series bool If `true` (default), terminates an active divergence if price or oscillator break
above the confirming pivot high.
Returns: A tuple containing comprehensive data for a detected bearish divergence.
regBear series bool `true` if a Regular bearish divergence (Class A) is active.
hidBear series bool `true` if a Hidden bearish divergence (Class B) is active.
exgBear series bool `true` if an Exaggerated bearish divergence (Class C) is active.
initPivotPrc series float Price value of the initial (older) pivot high.
initPivotOsz series float Oscillator value of the initial pivot high.
initPivotBar series int Bar index of the initial pivot high.
lastPivotPrc series float Price value of the last (confirming) pivot high.
lastPivotOsz series float Oscillator value of the last pivot high.
lastPivotBar series int Bar index of the last pivot high.
bullDivPos(regBull, hidBull, exgBull, rightLen, yPos)
Calculates the plottable data series for bullish divergences. It manages
the complex state of a persistent signal's plotting window to ensure
gap-free and accurately anchored visualization.
Parameters:
regBull (bool) : series bool The regular bullish divergence flag from `bullDiv`.
hidBull (bool) : series bool The hidden bullish divergence flag from `bullDiv`.
exgBull (bool) : series bool The exaggerated bullish divergence flag from `bullDiv`.
rightLen (int) : series int The same `rightLen` value used in `bullDiv` for correct timing.
yPos (float) : series float The series providing the base Y-coordinate for the shapes (e.g., `low`).
Returns: A tuple of three `series float` for plotting bullish divergences.
regBullPosY series float Contains the static anchor Y-value for Regular divergences where a shape should be plotted; `na` otherwise.
hidBullPosY series float Contains the static anchor Y-value for Hidden divergences where a shape should be plotted; `na` otherwise.
exgBullPosY series float Contains the static anchor Y-value for Exaggerated divergences where a shape should be plotted; `na` otherwise.
bearDivPos(regBear, hidBear, exgBear, rightLen, yPos)
Calculates the plottable data series for bearish divergences. It manages
the complex state of a persistent signal's plotting window to ensure
gap-free and accurately anchored visualization.
Parameters:
regBear (bool) : series bool The regular bearish divergence flag from `bearDiv`.
hidBear (bool) : series bool The hidden bearish divergence flag from `bearDiv`.
exgBear (bool) : series bool The exaggerated bearish divergence flag from `bearDiv`.
rightLen (int) : series int The same `rightLen` value used in `bearDiv` for correct timing.
yPos (float) : series float The series providing the base Y-coordinate for the shapes (e.g., `high`).
Returns: A tuple of three `series float` for plotting bearish divergences.
regBearPosY series float Contains the static anchor Y-value for Regular divergences where a shape should be plotted; `na` otherwise.
hidBearPosY series float Contains the static anchor Y-value for Hidden divergences where a shape should be plotted; `na` otherwise.
exgBearPosY series float Contains the static anchor Y-value for Exaggerated divergences where a shape should be plotted; `na` otherwise.
marketStructure(highSrc, lowSrc, leftLen, rightLen, srcTol)
Analyzes the market structure by identifying pivot points, classifying
their sequence (e.g., Higher Highs, Lower Lows), and determining the
prevailing trend state.
Parameters:
highSrc (float) : series float Price series for pivot high detection (e.g., `high`).
lowSrc (float) : series float Price series for pivot low detection (e.g., `low`).
leftLen (int) : series int Number of bars to the left of a pivot (default 5).
rightLen (int) : series int Number of bars to the right of a pivot (default 5).
srcTol (float) : series float Percentage tolerance to consider two pivots as 'equal' (default 0.05%).
Returns: A tuple containing detailed market structure information.
pivType series PivType The type of the most recently formed pivot (e.g., `hh`, `ll`).
lastPivHi series float The price level of the last confirmed pivot high.
lastPivLo series float The price level of the last confirmed pivot low.
lastPiv series float The price level of the last confirmed pivot (either high or low).
pivHiBroken series bool `true` if the price has broken above the last pivot high.
pivLoBroken series bool `true` if the price has broken below the last pivot low.
trendState series TrendState The current trend state (`up`, `down`, or `neutral`).

LibTmFrLibrary "LibTmFr"
This is a utility library for handling timeframes and
multi-timeframe (MTF) analysis in Pine Script. It provides a
collection of functions designed to handle common tasks related
to period detection, session alignment, timeframe construction,
and time calculations, forming a foundation for
MTF indicators.
Key Capabilities:
1. **MTF Period Engine:** The library includes functions for
managing higher-timeframe (HTF) periods.
- **Period Detection (`isNewPeriod`):** Detects the first bar
of a given timeframe. It includes custom logic to handle
multi-month and multi-year intervals where
`timeframe.change()` may not be sufficient.
- **Bar Counting (`sinceNewPeriod`):** Counts the number of
bars that have passed in the current HTF period or
returns the final count for a completed historical period.
2. **Automatic Timeframe Selection:** Offers functions for building
a top-down analysis framework:
- **Automatic HTF (`autoHTF`):** Suggests a higher timeframe
(HTF) for broader context based on the current timeframe.
- **Automatic LTF (`autoLTF`):** Suggests an appropriate lower
timeframe (LTF) for granular intra-bar analysis.
3. **Timeframe Manipulation and Comparison:** Includes tools for
working with timeframe strings:
- **Build & Split (`buildTF`, `splitTF`):** Functions to
programmatically construct valid Pine Script timeframe
strings (e.g., "4H") and parse them back into their
numeric and unit components.
- **Comparison (`isHigherTF`, `isActiveTF`, `isLowerTF`):**
A set of functions to check if a given timeframe is
higher, lower, or the same as the script's active timeframe.
- **Multiple Validation (`isMultipleTF`):** Checks if a
higher timeframe is a practical multiple of the current
timeframe. This is based on the assumption that checking
if recent, completed HTF periods contained more than one
bar is a valid proxy for preventing data gaps.
4. **Timestamp Interpolation:** Contains an `interpTimestamp()`
function that calculates an absolute timestamp by
interpolating at a given percentage across a specified
range of bars (e.g., 50% of the way through the last
20 bars), enabling time calculations at a resolution
finer than the chart's native bars.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
buildTF(quantity, unit)
Builds a Pine Script timeframe string from a numeric quantity and a unit enum.
The resulting string can be used with `request.security()` or `input.timeframe`.
Parameters:
quantity (int) : series int Number to specifie how many `unit` the timeframe spans.
unit (series TFUnit) : series TFUnit The size category for the bars.
Returns: series string A Pine-style timeframe identifier, e.g.
"5S" → 5-seconds bars
"30" → 30-minute bars
"120" → 2-hour bars
"1D" → daily bars
"3M" → 3-month bars
"24M" → 2-year bars
splitTF(tf)
Splits a Pine‑timeframe identifier into numeric quantity and unit (TFUnit).
Parameters:
tf (string) : series string Timeframe string, e.g.
"5S", "30", "120", "1D", "3M", "24M".
Returns:
quantity series int The numeric value of the timeframe (e.g., 15 for "15", 3 for "3M").
unit series TFUnit The unit of the timeframe (e.g., TFUnit.minutes, TFUnit.months).
Notes on strings without a suffix:
• Pure digits are minutes; if divisible by 60, they are treated as hours.
• An "M" suffix is months; if divisible by 12, it is converted to years.
autoHTF(tf)
Picks an appropriate **higher timeframe (HTF)** relative to the selected timeframe.
It steps up along a coarse ladder to produce sensible jumps for top‑down analysis.
Mapping → chosen HTF:
≤ 1 min → 60 (1h) ≈ ×60
≤ 3 min → 180 (3h) ≈ ×60
≤ 5 min → 240 (4h) ≈ ×48
≤ 15 min → D (1 day) ≈ ×26–×32 (regular session 6.5–8 h)
> 15 min → W (1 week) ≈ ×64–×80 for 30m; varies with input
≤ 1 h → W (1 week) ≈ ×32–×40
≤ 4 h → M (1 month) ≈ ×36–×44 (~22 trading days / month)
> 4 h → 3M (3 months) ≈ ×36–×66 (e.g., 12h→×36–×44; 8h→×53–×66)
≤ 1 day → 3M (3 months) ≈ ×60–×66 (~20–22 trading days / month)
> 1 day → 12M (1 year) ≈ ×(252–264)/quantity
≤ 1 week → 12M (1 year) ≈ ×52
> 1 week → 48M (4 years) ≈ ×(208)/quantity
= 1 M → 48M (4 years) ≈ ×48
> 1 M → error ("HTF too big")
any → error ("HTF too big")
Notes:
• Inputs in months or years are restricted: only 1M is allowed; larger months/any years throw.
• Returns a Pine timeframe string usable in `request.security()` and `input.timeframe`.
Parameters:
tf (string) : series string Selected timeframe (e.g., "D", "240", or `timeframe.period`).
Returns: series string Suggested higher timeframe.
autoLTF(tf)
Selects an appropriate **lower timeframe LTF)** for intra‑bar evaluation
based on the selected timeframe. The goal is to keep intra‑bar
loops performant while providing enough granularity.
Mapping → chosen LTF:
≤ 1 min → 1S ≈ ×60
≤ 5 min → 5S ≈ ×60
≤ 15 min → 15S ≈ ×60
≤ 30 min → 30S ≈ ×60
> 30 min → 60S (1m) ≈ ×31–×59 (for 31–59 minute charts)
≤ 1 h → 1 (1m) ≈ ×60
≤ 2 h → 2 (2m) ≈ ×60
≤ 4 h → 5 (5m) ≈ ×48
> 4 h → 15 (15m) ≈ ×24–×48 (e.g., 6h→×24, 8h→×32, 12h→×48)
≤ 1 day → 15 (15m) ≈ ×26–×32 (regular sessions ~6.5–8h)
> 1 day → 60 (60m) ≈ ×(26–32) per day × quantity
≤ 1 week → 60 (60m) ≈ ×32–×40 (≈5 sessions of ~6.5–8h)
> 1 week → 240 (4h) ≈ ×(8–10) per week × quantity
≤ 1 M → 240 (4h) ≈ ×33–×44 (~20–22 sessions × 6.5–8h / 4h)
≤ 3 M → D (1d) ≈ ×(20–22) per month × quantity
> 3 M → W (1w) ≈ ×(4–5) per month × quantity
≤ 1 Y → W (1w) ≈ ×52
> 1 Y → M (1M) ≈ ×12 per year × quantity
Notes:
• Ratios for D/W/M are given as ranges because they depend on
**regular session length** (typically ~6.5–8h, not 24h).
• Returned strings can be used with `request.security()` and `input.timeframe`.
Parameters:
tf (string) : series string Selected timeframe (e.g., "D", "240", or timeframe.period).
Returns: series string Suggested lower TF to use for intra‑bar work.
isNewPeriod(tf, offset)
Returns `true` when a new session-aligned period begins, or on the Nth bar of that period.
Parameters:
tf (string) : series string Target higher timeframe (e.g., "D", "W", "M").
offset (simple int) : simple int 0 → checks for the first bar of the new period.
1+ → checks for the N-th bar of the period.
Returns: series bool `true` if the condition is met.
sinceNewPeriod(tf, offset)
Counts how many bars have passed within a higher timeframe (HTF) period.
For daily, weekly, and monthly resolutions, the period is aligned with the trading session.
Parameters:
tf (string) : series string Target parent timeframe (e.g., "60", "D").
offset (simple int) : simple int 0 → Running count for the current period.
1+ → Finalized count for the Nth most recent *completed* period.
Returns: series int Number of bars.
isHigherTF(tf, main)
Returns `true` when the selected timeframe represents a
higher resolution than the active timeframe.
Parameters:
tf (string) : series string Selected timeframe.
main (bool) : series bool When `true`, the comparison is made against the chart's main timeframe
instead of the script's active timeframe. Optional. Defaults to `false`.
Returns: series bool `true` if `tf` > active TF; otherwise `false`.
isActiveTF(tf, main)
Returns `true` when the selected timeframe represents the
exact resolution of the active timeframe.
Parameters:
tf (string) : series string Selected timeframe.
main (bool) : series bool When `true`, the comparison is made against the chart's main timeframe
instead of the script's active timeframe. Optional. Defaults to `false`.
Returns: series bool `true` if `tf` == active TF; otherwise `false`.
isLowerTF(tf, main)
Returns `true` when the selected timeframe represents a
lower resolution than the active timeframe.
Parameters:
tf (string) : series string Selected timeframe.
main (bool) : series bool When `true`, the comparison is made against the chart's main timeframe
instead of the script's active timeframe. Optional. Defaults to `false`.
Returns: series bool `true` if `tf` < active TF; otherwise `false`.
isMultipleTF(tf)
Returns `true` if the selected timeframe (`tf`) is a practical multiple
of the active skript's timeframe. It verifies this by checking if `tf` is a higher timeframe
that has consistently contained more than one bar of the skript's timeframe in recent periods.
The period detection is session-aware.
Parameters:
tf (string) : series string The higher timeframe to check.
Returns: series bool `true` if `tf` is a practical multiple; otherwise `false`.
interpTimestamp(offStart, offEnd, pct)
Calculates a precise absolute timestamp by interpolating within a bar range based on a percentage.
This version works with RELATIVE bar offsets from the current bar.
Parameters:
offStart (int) : series int The relative offset of the starting bar (e.g., 10 for 10 bars ago).
offEnd (int) : series int The relative offset of the ending bar (e.g., 1 for 1 bar ago). Must be <= offStart.
pct (float) : series float The percentage of the bar range to measure (e.g., 50.5 for 50.5%).
Values are clamped to the range.
Returns: series int The calculated, interpolated absolute Unix timestamp in milliseconds.

LibVolmLibrary "LibVolm"
This library provides a collection of core functions for volume and
money flow analysis. It offers implementations of several classic
volume-based indicators, with a focus on flexibility
for applications like multi-timeframe and session-based analysis.
Key Features:
1. **Suite of Classic Volume Indicators:** Includes standard
implementations of several foundational indicators:
- **On Balance Volume (`obv`):** A momentum indicator that
accumulates volume based on price direction.
- **Accumulation/Distribution Line (`adLine`):** Measures cumulative
money flow using the close's position within the bar's range.
- **Chaikin Money Flow (`cmf`):** An oscillator version of the ADL
that measures money flow over a specified lookback period.
2. **Anchored/Resettable Indicators:** The library includes flexible,
resettable indicators ideal for cyclical analysis:
- **Anchored VWAP (`vwap`):** Calculates a Volume Weighted Average
Price that can be reset on any user-defined `reset` condition.
It returns both the VWAP and the number of bars (`prdBars`) in
the current period.
- **Resettable CVD (`cvd`):** Computes a Cumulative Volume Delta
that can be reset on a custom `reset` anchor. The function
also tracks and returns the highest (`hi`) and lowest (`lo`)
delta values reached within the current period.
(Note: The delta sign is determined by a specific logic:
it first checks close vs. open, then close vs. prior
close, and persists the last non-zero sign).
3. **Volume Sanitization:** All functions that use the built-in
`volume` variable automatically sanitize it via an internal
function. This process replaces `na` values with 0 and ensures
no negative volume values are used, providing stable calculations.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
obv(price)
Calculates the On Balance Volume (OBV) cumulative indicator.
Parameters:
price (float) : series float Source price series, typically the close.
Returns: series float Cumulative OBV value.
adLine()
Computes the Accumulation/Distribution Line (AD Line).
Returns: series float Cumulative AD Line value.
cmf(length)
Computes Chaikin Money Flow (CMF).
Parameters:
length (int) : series int Lookback length for the CMF calculation.
Returns: series float CMF value.
vwap(price, reset)
Calculates an anchored Volume Weighted Average Price (VWAP).
Parameters:
price (float) : series float Source price series (usually *close*).
reset (bool) : series bool A signal that is *true* on the bar where the
accumulation should be reset.
Returns:
vwap series float The calculated Volume Weighted Average Price for the current period.
prdBars series int The number of bars that have passed since the last reset.
cvd(reset)
Calculates a resettable, cumulative Volume Delta (CVD).
It accumulates volume delta and tracks its high/low range. The
accumulation is reset to zero whenever the `reset` condition is true.
This is useful for session-based analysis, intra-bar calculations,
or any other custom-anchored accumulation.
Parameters:
reset (bool) : series bool A signal that is *true* on the bar where the
accumulation should be reset.
Returns:
cum series float The current cumulative volume delta.
hi series float The highest peak the cumulative delta has reached in the current period.
lo series float The lowest trough the cumulative delta has reached in the current period.

LibMvAvLibrary "LibMvAv"
This library provides a unified interface for calculating a
wide variety of moving averages. It is designed to simplify
indicator development by consolidating numerous MA calculations
into a single function and integrating the weighting
capabilities from the `LibWght` library.
Key Features:
1. **All-in-One MA Function:** The core of the library is the
`ma()` function. Users can select the desired calculation
method via the `MAType` enum, which helps create
cleaner and more maintainable code compared to using
many different `ta.*` or custom functions.
2. **Comprehensive Selection of MA Types:** It provides a
selection of 12 different moving averages, covering
common Pine Script built-ins and their weighted counterparts:
- **Standard MAs:** SMA, EMA, WMA, RMA (Wilder's), HMA (Hull), and
LSMA (Least Squares / Linear Regression).
- **Weighted MAs:** Weight-enhanced versions of the above
(WSMA, WEMA, WWMA, WRMA, WHMA, WLSMA).
3. **Integrated Weighting:** The library provides weighted versions
for each of its standard MA types (e.g., `wsma` alongside `sma`).
By acting as a dispatcher, the `ma()` function allows these
weighted calculations to be called using the optional
`weight` parameter, which are then processed by the `LibWght`
library.
4. **Simple API:** The library internally handles the logic of
choosing the correct function based on the selected `MAType`.
The user only needs to provide the source, length, and
optional weight, simplifying the development process.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
ma(maType, source, length, weight)
Returns the requested moving average.
Parameters:
maType (simple MAType) : simple MAType Desired type (see enum above).
source (float) : series float Data series to smooth.
length (simple int) : simple int Look-back / period length.
weight (float) : series float Weight series (default = na)
Returns: series float Moving-average value.

LibWghtLibrary "LibWght"
This is a library of mathematical and statistical functions
designed for quantitative analysis in Pine Script. Its core
principle is the integration of a custom weighting series
(e.g., volume) into a wide array of standard technical
analysis calculations.
Key Capabilities:
1. **Universal Weighting:** All exported functions accept a `weight`
parameter. This allows standard calculations (like moving
averages, RSI, and standard deviation) to be influenced by an
external data series, such as volume or tick count.
2. **Weighted Averages and Indicators:** Includes a comprehensive
collection of weighted functions:
- **Moving Averages:** `wSma`, `wEma`, `wWma`, `wRma` (Wilder's),
`wHma` (Hull), and `wLSma` (Least Squares / Linear Regression).
- **Oscillators & Ranges:** `wRsi`, `wAtr` (Average True Range),
`wTr` (True Range), and `wR` (High-Low Range).
3. **Volatility Decomposition:** Provides functions to decompose
total variance into distinct components for market analysis.
- **Two-Way Decomposition (`wTotVar`):** Separates variance into
**between-bar** (directional) and **within-bar** (noise)
components.
- **Three-Way Decomposition (`wLRTotVar`):** Decomposes variance
relative to a linear regression into **Trend** (explained by
the LR slope), **Residual** (mean-reversion around the
LR line), and **Within-Bar** (noise) components.
- **Local Volatility (`wLRLocTotStdDev`):** Measures the total
"noise" (within-bar + residual) around the trend line.
4. **Weighted Statistics and Regression:** Provides a robust
function for Weighted Linear Regression (`wLinReg`) and a
full suite of related statistical measures:
- **Between-Bar Stats:** `wBtwVar`, `wBtwStdDev`, `wBtwStdErr`.
- **Residual Stats:** `wResVar`, `wResStdDev`, `wResStdErr`.
5. **Fallback Mechanism:** All functions are designed for reliability.
If the total weight over the lookback period is zero (e.g., in
a no-volume period), the algorithms automatically fall back to
their unweighted, uniform-weight equivalents (e.g., `wSma`
becomes a standard `ta.sma`), preventing errors and ensuring
continuous calculation.
---
**DISCLAIMER**
This library is provided "AS IS" and for informational and
educational purposes only. It does not constitute financial,
investment, or trading advice.
The author assumes no liability for any errors, inaccuracies,
or omissions in the code. Using this library to build
trading indicators or strategies is entirely at your own risk.
As a developer using this library, you are solely responsible
for the rigorous testing, validation, and performance of any
scripts you create based on these functions. The author shall
not be held liable for any financial losses incurred directly
or indirectly from the use of this library or any scripts
derived from it.
wSma(source, weight, length)
Weighted Simple Moving Average (linear kernel).
Parameters:
source (float) : series float Data to average.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 1.
Returns: series float Linear-kernel weighted mean; falls back to
the arithmetic mean if Σweight = 0.
wEma(source, weight, length)
Weighted EMA (exponential kernel).
Parameters:
source (float) : series float Data to average.
weight (float) : series float Weight series.
length (simple int) : simple int Look-back length ≥ 1.
Returns: series float Exponential-kernel weighted mean; falls
back to classic EMA if Σweight = 0.
wWma(source, weight, length)
Weighted WMA (linear kernel).
Parameters:
source (float) : series float Data to average.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 1.
Returns: series float Linear-kernel weighted mean; falls back to
classic WMA if Σweight = 0.
wRma(source, weight, length)
Weighted RMA (Wilder kernel, α = 1/len).
Parameters:
source (float) : series float Data to average.
weight (float) : series float Weight series.
length (simple int) : simple int Look-back length ≥ 1.
Returns: series float Wilder-kernel weighted mean; falls back to
classic RMA if Σweight = 0.
wHma(source, weight, length)
Weighted HMA (linear kernel).
Parameters:
source (float) : series float Data to average.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 1.
Returns: series float Linear-kernel weighted mean; falls back to
classic HMA if Σweight = 0.
wRsi(source, weight, length)
Weighted Relative Strength Index.
Parameters:
source (float) : series float Price series.
weight (float) : series float Weight series.
length (simple int) : simple int Look-back length ≥ 1.
Returns: series float Weighted RSI; uniform if Σw = 0.
wAtr(tr, weight, length)
Weighted ATR (Average True Range).
Implemented as WRMA on *true range*.
Parameters:
tr (float) : series float True Range series.
weight (float) : series float Weight series.
length (simple int) : simple int Look-back length ≥ 1.
Returns: series float Weighted ATR; uniform weights if Σw = 0.
wTr(tr, weight, length)
Weighted True Range over a window.
Parameters:
tr (float) : series float True Range series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 1.
Returns: series float Weighted mean of TR; uniform if Σw = 0.
wR(r, weight, length)
Weighted High-Low Range over a window.
Parameters:
r (float) : series float High-Low per bar.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 1.
Returns: series float Weighted mean of range; uniform if Σw = 0.
wBtwVar(source, weight, length, biased)
Weighted Between Variance (biased/unbiased).
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns:
variance series float The calculated between-bar variance (σ²btw), either biased or unbiased.
sumW series float The sum of weights over the lookback period (Σw).
sumW2 series float The sum of squared weights over the lookback period (Σw²).
wBtwStdDev(source, weight, length, biased)
Weighted Between Standard Deviation.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float σbtw uniform if Σw = 0.
wBtwStdErr(source, weight, length, biased)
Weighted Between Standard Error.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float √(σ²btw / N_eff) uniform if Σw = 0.
wTotVar(mu, sigma, weight, length, biased)
Weighted Total Variance (= between-group + within-group).
Useful when each bar represents an aggregate with its own
mean* and pre-estimated σ (e.g., second-level ranges inside a
1-minute bar). Assumes the *weight* series applies to both the
group means and their σ estimates.
Parameters:
mu (float) : series float Group means (e.g., HL2 of 1-second bars).
sigma (float) : series float Pre-estimated σ of each group (same basis).
weight (float) : series float Weight series (volume, ticks, …).
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns:
varBtw series float The between-bar variance component (σ²btw).
varWtn series float The within-bar variance component (σ²wtn).
sumW series float The sum of weights over the lookback period (Σw).
sumW2 series float The sum of squared weights over the lookback period (Σw²).
wTotStdDev(mu, sigma, weight, length, biased)
Weighted Total Standard Deviation.
Parameters:
mu (float) : series float Group means (e.g., HL2 of 1-second bars).
sigma (float) : series float Pre-estimated σ of each group (same basis).
weight (float) : series float Weight series (volume, ticks, …).
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float σtot.
wTotStdErr(mu, sigma, weight, length, biased)
Weighted Total Standard Error.
SE = √( total variance / N_eff ) with the same effective sample
size logic as `wster()`.
Parameters:
mu (float) : series float Group means (e.g., HL2 of 1-second bars).
sigma (float) : series float Pre-estimated σ of each group (same basis).
weight (float) : series float Weight series (volume, ticks, …).
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float √(σ²tot / N_eff).
wLinReg(source, weight, length)
Weighted Linear Regression.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 2.
Returns:
mid series float The estimated value of the regression line at the most recent bar.
slope series float The slope of the regression line.
intercept series float The intercept of the regression line.
wResVar(source, weight, midLine, slope, length, biased)
Weighted Residual Variance.
linear regression – optionally biased (population) or
unbiased (sample).
Parameters:
source (float) : series float Data series.
weight (float) : series float Weighting series (volume, etc.).
midLine (float) : series float Regression value at the last bar.
slope (float) : series float Slope per bar.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population variance (σ²_P), denominator ≈ N_eff.
false → sample variance (σ²_S), denominator ≈ N_eff - 2.
(Adjusts for 2 degrees of freedom lost to the regression).
Returns:
variance series float The calculated residual variance (σ²res), either biased or unbiased.
sumW series float The sum of weights over the lookback period (Σw).
sumW2 series float The sum of squared weights over the lookback period (Σw²).
wResStdDev(source, weight, midLine, slope, length, biased)
Weighted Residual Standard Deviation.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
midLine (float) : series float Regression value at the last bar.
slope (float) : series float Slope per bar.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float σres; uniform if Σw = 0.
wResStdErr(source, weight, midLine, slope, length, biased)
Weighted Residual Standard Error.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
midLine (float) : series float Regression value at the last bar.
slope (float) : series float Slope per bar.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population (biased); false → sample.
Returns: series float √(σ²res / N_eff); uniform if Σw = 0.
wLRTotVar(mu, sigma, weight, midLine, slope, length, biased)
Weighted Linear-Regression Total Variance **around the
window’s weighted mean μ**.
σ²_tot = E_w ⟶ *within-group variance*
+ Var_w ⟶ *residual variance*
+ Var_w ⟶ *trend variance*
where each bar i in the look-back window contributes
m_i = *mean* (e.g. 1-sec HL2)
σ_i = *sigma* (pre-estimated intrabar σ)
w_i = *weight* (volume, ticks, …)
ŷ_i = b₀ + b₁·x (value of the weighted LR line)
r_i = m_i − ŷ_i (orthogonal residual)
Parameters:
mu (float) : series float Per-bar mean m_i.
sigma (float) : series float Pre-estimated σ_i of each bar.
weight (float) : series float Weight series w_i (≥ 0).
midLine (float) : series float Regression value at the latest bar (ŷₙ₋₁).
slope (float) : series float Slope b₁ of the regression line.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population; false → sample.
Returns:
varRes series float The residual variance component (σ²res).
varWtn series float The within-bar variance component (σ²wtn).
varTrd series float The trend variance component (σ²trd), explained by the linear regression.
sumW series float The sum of weights over the lookback period (Σw).
sumW2 series float The sum of squared weights over the lookback period (Σw²).
wLRTotStdDev(mu, sigma, weight, midLine, slope, length, biased)
Weighted Linear-Regression Total Standard Deviation.
Parameters:
mu (float) : series float Per-bar mean m_i.
sigma (float) : series float Pre-estimated σ_i of each bar.
weight (float) : series float Weight series w_i (≥ 0).
midLine (float) : series float Regression value at the latest bar (ŷₙ₋₁).
slope (float) : series float Slope b₁ of the regression line.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population; false → sample.
Returns: series float √(σ²tot).
wLRTotStdErr(mu, sigma, weight, midLine, slope, length, biased)
Weighted Linear-Regression Total Standard Error.
SE = √( σ²_tot / N_eff ) with N_eff = Σw² / Σw² (like in wster()).
Parameters:
mu (float) : series float Per-bar mean m_i.
sigma (float) : series float Pre-estimated σ_i of each bar.
weight (float) : series float Weight series w_i (≥ 0).
midLine (float) : series float Regression value at the latest bar (ŷₙ₋₁).
slope (float) : series float Slope b₁ of the regression line.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population; false → sample.
Returns: series float √((σ²res, σ²wtn, σ²trd) / N_eff).
wLRLocTotStdDev(mu, sigma, weight, midLine, slope, length, biased)
Weighted Linear-Regression Local Total Standard Deviation.
Measures the total "noise" (within-bar + residual) around the trend.
Parameters:
mu (float) : series float Per-bar mean m_i.
sigma (float) : series float Pre-estimated σ_i of each bar.
weight (float) : series float Weight series w_i (≥ 0).
midLine (float) : series float Regression value at the latest bar (ŷₙ₋₁).
slope (float) : series float Slope b₁ of the regression line.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population; false → sample.
Returns: series float √(σ²wtn + σ²res).
wLRLocTotStdErr(mu, sigma, weight, midLine, slope, length, biased)
Weighted Linear-Regression Local Total Standard Error.
Parameters:
mu (float) : series float Per-bar mean m_i.
sigma (float) : series float Pre-estimated σ_i of each bar.
weight (float) : series float Weight series w_i (≥ 0).
midLine (float) : series float Regression value at the latest bar (ŷₙ₋₁).
slope (float) : series float Slope b₁ of the regression line.
length (int) : series int Look-back length ≥ 2.
biased (bool) : series bool true → population; false → sample.
Returns: series float √((σ²wtn + σ²res) / N_eff).
wLSma(source, weight, length)
Weighted Least Square Moving Average.
Parameters:
source (float) : series float Data series.
weight (float) : series float Weight series.
length (int) : series int Look-back length ≥ 2.
Returns: series float Least square weighted mean. Falls back
to unweighted regression if Σw = 0.

mysourcetypesncsLibrary "mysourcetypes"
Libreria personale per sorgenti estese (Close, Open, High, Low, Median, Typical, Weighted, Average, Average Median Body, Trend Biased, Trend Biased Extreme, Volume Body, Momentum Biased, Volatility Adjusted, Body Dominance, Shadow Biased, Gap Aware, Rejection Biased, Range Position, Adaptive Trend, Pressure Balanced, Impulse Wave)
rclose()
Regular Close
Returns: Close price
ropen()
Regular Open
Returns: Open price
rhigh()
Regular High
Returns: High price
rlow()
Regular Low
Returns: Low price
rmedian()
Regular Median (HL2)
Returns: (High + Low) / 2
rtypical()
Regular Typical (HLC3)
Returns: (High + Low + Close) / 3
rweighted()
Regular Weighted (HLCC4)
Returns: (High + Low + Close + Close) / 4
raverage()
Regular Average (OHLC4)
Returns: (Open + High + Low + Close) / 4
ravemedbody()
Average Median Body
Returns: (Open + Close) / 2
rtrendb()
Trend Biased Regular
Returns: Trend-weighted price
rtrendbext()
Trend Biased Extreme
Returns: Extreme trend-weighted price
rvolbody()
Volume Weighted Body
Returns: Body midpoint weighted by volume intensity
rmomentum()
Momentum Biased
Returns: Price biased towards momentum direction
rvolatility()
Volatility Adjusted
Returns: Price adjusted by candle's volatility
rbodydominance()
Body Dominance
Returns: Emphasizes body over wicks
rshadowbias()
Shadow Biased
Returns: Price biased by shadow length
rgapaware()
Gap Aware
Returns: Considers gap between candles
rrejection()
Rejection Biased
Returns: Emphasizes price rejection levels
rrangeposition()
Range Position
Returns: Where close sits within the candle range (0-100%)
radaptivetrend()
Adaptive Trend
Returns: Adapts based on recent trend strength
rpressure()
Pressure Balanced
Returns: Balances buying/selling pressure within candle
rimpulse()
Impulse Wave
Returns: Detects impulsive moves vs corrections

TimezoneDiffLibLibrary "TimezoneDiffLib"
get_tz_diff(tz1, tz2)
Parameters:
tz1 (string)
tz2 (string)

BossExoticMAs
A next-generation moving average and smoothing library by TheStopLossBoss, featuring premium adaptive, exotic, and DSP-inspired filters — optimized for Pine Script® v6 and designed for Traders who demand precision and beauty.
> BossExoticMAs is a complete moving average and signal-processing toolkit built for Pine Script v6.
It combines the essential trend filters (SMA, EMA, WMA, etc.) with advanced, high-performance exotic types used by quants, algo designers, and adaptive systems.
Each function is precision-tuned for stability, speed, and visual clarity — perfect for building custom baselines, volatility filters, dynamic ribbons, or hybrid signal engines.
Includes built-in color gradient theming powered by the exclusive BossGradient —
//Key Features
✅ Full Moving Average Set
SMA, EMA, ZEMA, WMA, HMA, WWMA, SMMA
DEMA, TEMA, T3 (Tillson)
ALMA, KAMA, LSMA
VMA, VAMA, FRAMA
✅ Signal Filters
One-Euro Filter (Crispin/Casiez implementation)
ATR-bounded Range Filter
✅ Color Engine
lerpColor() safe blending using color.from_gradient
Thematic gradient palettes: STOPLOSS, VAPORWAVE, ROYAL FLAME, MATRIX FLOW
Exclusive: BOSS GRADIENT
✅ Helper Functions
Clamping, normalization, slope detection, tick delta
Slope-based dynamic color control via slopeThemeColor()
🧠 Usage Example
//@version=6
indicator("Boss Exotic MA Demo", overlay=true)
import TheStopLossBoss/BossExoticMAs/1 as boss
len = input.int(50, "Length")
atype = input.string("T3", "MA Type", options= )
t3factor = input.float(0.7, "T3 β", step=0.05)
smoothColor = boss.slopeThemeColor(close, "BOSS GRADIENT", 0.001)ma = boss.maSelect(close, len, atype, t3factor, 0.85, 14)
plot(ma, "Boss Exotic MA", color=smoothColor, linewidth=2)
---
🔑 Notes
Built exclusively for Pine Script® v6
Library designed for import use — all exports are prefixed cleanly (boss.functionName())
Some functions maintain internal state (var-based). Warnings are safe to ignore — adaptive design choice.
Each MA output is non-repainting and mathematically stable.
---
📜 Author
TheStopLossBoss
Designer of precision trading systems and custom adaptive algorithms.
Follow for exclusive releases, educational material, and full-stack trend solutions.
movingaverage, trend, adaptive, filter, volatility, smoothing, quant, technicalanalysis, bossgradient, t3, alma, frama, vma
LogNormalLibrary "LogNormal"
A collection of functions used to model skewed distributions as log-normal.
Prices are commonly modeled using log-normal distributions (ie. Black-Scholes) because they exhibit multiplicative changes with long tails; skewed exponential growth and high variance. This approach is particularly useful for understanding price behavior and estimating risk, assuming continuously compounding returns are normally distributed.
Because log space analysis is not as direct as using math.log(price) , this library extends the Error Functions library to make working with log-normally distributed data as simple as possible.
- - -
QUICK START
Import library into your project
Initialize model with a mean and standard deviation
Pass model params between methods to compute various properties
var LogNorm model = LN.init(arr.avg(), arr.stdev()) // Assumes the library is imported as LN
var mode = model.mode()
Outputs from the model can be adjusted to better fit the data.
var Quantile data = arr.quantiles()
var more_accurate_mode = mode.fit(model, data) // Fits value from model to data
Inputs to the model can also be adjusted to better fit the data.
datum = 123.45
model_equivalent_datum = datum.fit(data, model) // Fits value from data to the model
area_from_zero_to_datum = model.cdf(model_equivalent_datum)
- - -
TYPES
There are two requisite UDTs: LogNorm and Quantile . They are used to pass parameters between functions and are set automatically (see Type Management ).
LogNorm
Object for log space parameters and linear space quantiles .
Fields:
mu (float) : Log space mu ( µ ).
sigma (float) : Log space sigma ( σ ).
variance (float) : Log space variance ( σ² ).
quantiles (Quantile) : Linear space quantiles.
Quantile
Object for linear quantiles, most similar to a seven-number summary .
Fields:
Q0 (float) : Smallest Value
LW (float) : Lower Whisker Endpoint
LC (float) : Lower Whisker Crosshatch
Q1 (float) : First Quartile
Q2 (float) : Second Quartile
Q3 (float) : Third Quartile
UC (float) : Upper Whisker Crosshatch
UW (float) : Upper Whisker Endpoint
Q4 (float) : Largest Value
IQR (float) : Interquartile Range
MH (float) : Midhinge
TM (float) : Trimean
MR (float) : Mid-Range
- - -
TYPE MANAGEMENT
These functions reliably initialize and update the UDTs. Because parameterization is interdependent, avoid setting the LogNorm and Quantile fields directly .
init(mean, stdev, variance)
Initializes a LogNorm object.
Parameters:
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
set(ln, mean, stdev, variance)
Transforms linear measurements into log space parameters for a LogNorm object.
Parameters:
ln (LogNorm) : Object containing log space parameters.
mean (float) : Linearly measured mean.
stdev (float) : Linearly measured standard deviation.
variance (float) : Linearly measured variance.
Returns: LogNorm Object
quantiles(arr)
Gets empirical quantiles from an array of floats.
Parameters:
arr (array) : Float array object.
Returns: Quantile Object
- - -
DESCRIPTIVE STATISTICS
Using only the initialized LogNorm parameters, these functions compute a model's central tendency and standardized moments.
mean(ln)
Computes the linear mean from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
median(ln)
Computes the linear median from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
mode(ln)
Computes the linear mode from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
variance(ln)
Computes the linear variance from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
skewness(ln)
Computes the linear skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
kurtosis(ln, excess)
Computes the linear kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Kurtosis (true) or regular Kurtosis (false).
Returns: Between 0 and ∞
hyper_skewness(ln)
Computes the linear hyper skewness from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
Returns: Between 0 and ∞
hyper_kurtosis(ln, excess)
Computes the linear hyper kurtosis from log space parameters.
Parameters:
ln (LogNorm) : Object containing log space parameters.
excess (bool) : Excess Hyper Kurtosis (true) or regular Hyper Kurtosis (false).
Returns: Between 0 and ∞
- - -
DISTRIBUTION FUNCTIONS
These wrap Gaussian functions to make working with model space more direct. Because they are contained within a log-normal library, they describe estimations relative to a log-normal curve, even though they fundamentally measure a Gaussian curve.
pdf(ln, x, empirical_quantiles)
A Probability Density Function estimates the probability density . For clarity, density is not a probability .
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate for which a density will be estimated.
empirical_quantiles (Quantile) : Quantiles as observed in the data (optional).
Returns: Between 0 and ∞
cdf(ln, x, precise)
A Cumulative Distribution Function estimates the area under a Log-Normal curve between Zero and a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ccdf(ln, x, precise)
A Complementary Cumulative Distribution Function estimates the area under a Log-Normal curve between a linear X coordinate and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
cdfinv(ln, a, precise)
An Inverse Cumulative Distribution Function reverses the Log-Normal cdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
ccdfinv(ln, a, precise)
An Inverse Complementary Cumulative Distribution Function reverses the Log-Normal ccdf() by estimating the linear X coordinate from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
cdfab(ln, x1, x2, precise)
A Cumulative Distribution Function from A to B estimates the area under a Log-Normal curve between two linear X coordinates (A and B).
Parameters:
ln (LogNorm) : Object of log space parameters.
x1 (float) : First linear X coordinate .
x2 (float) : Second linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ott(ln, x, precise)
A One-Tailed Test transforms a linear X coordinate into an absolute Z Score before estimating the area under a Log-Normal curve between Z and Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 0.5
ttt(ln, x, precise)
A Two-Tailed Test transforms a linear X coordinate into symmetrical ± Z Scores before estimating the area under a Log-Normal curve from Zero to -Z, and +Z to Infinity.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
ottinv(ln, a, precise)
An Inverse One-Tailed Test reverses the Log-Normal ott() by estimating a linear X coordinate for the right tail from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Half a normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
tttinv(ln, a, precise)
An Inverse Two-Tailed Test reverses the Log-Normal ttt() by estimating two linear X coordinates from an area.
Parameters:
ln (LogNorm) : Object of log space parameters.
a (float) : Normalized area .
precise (bool) : Double precision (true) or single precision (false).
Returns: Linear space tuple :
- - -
UNCERTAINTY
Model-based measures of uncertainty, information, and risk.
sterr(sample_size, fisher_info)
The standard error of a sample statistic.
Parameters:
sample_size (float) : Number of observations.
fisher_info (float) : Fisher information.
Returns: Between 0 and ∞
surprisal(p, base)
Quantifies the information content of a single event.
Parameters:
p (float) : Probability of the event .
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
entropy(ln, base)
Computes the differential entropy (average surprisal).
Parameters:
ln (LogNorm) : Object of log space parameters.
base (float) : Logarithmic base (optional).
Returns: Between 0 and ∞
perplexity(ln, base)
Computes the average number of distinguishable outcomes from the entropy.
Parameters:
ln (LogNorm)
base (float) : Logarithmic base used for Entropy (optional).
Returns: Between 0 and ∞
value_at_risk(ln, p, precise)
Estimates a risk threshold under normal market conditions for a given confidence level.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
value_at_risk_inv(ln, value_at_risk, precise)
Reverses the value_at_risk() by estimating the confidence level from the risk threshold.
Parameters:
ln (LogNorm) : Object of log space parameters.
value_at_risk (float) : Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
conditional_value_at_risk(ln, p, precise)
Estimates the average loss beyond a confidence level, aka. expected shortfall.
Parameters:
ln (LogNorm) : Object of log space parameters.
p (float) : Probability threshold, aka. the confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_value_at_risk_inv(ln, conditional_value_at_risk, precise)
Reverses the conditional_value_at_risk() by estimating the confidence level of an average loss.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_value_at_risk (float) : Conditional Value at Risk.
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and 1
partial_expectation(ln, x, precise)
Estimates the partial expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and µ
partial_expectation_inv(ln, partial_expectation, precise)
Reverses the partial_expectation() by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
partial_expectation (float) : Partial Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
conditional_expectation(ln, x, precise)
Estimates the conditional expectation of a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between X and ∞
conditional_expectation_inv(ln, conditional_expectation, precise)
Reverses the conditional_expectation by estimating a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
conditional_expectation (float) : Conditional Expectation .
precise (bool) : Double precision (true) or single precision (false).
Returns: Between 0 and ∞
fisher(ln, log)
Computes the Fisher Information Matrix for the distribution, not a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the distribution
fisher(ln, x, log)
Computes the Fisher Information Matrix for a linear X coordinate, not the distribution itself.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
log (bool) : Sets if the matrix should be in log (true) or linear (false) space.
Returns: FIM for the linear X coordinate
confidence_interval(ln, x, sample_size, confidence, precise)
Estimates a confidence interval for a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate .
sample_size (float) : Number of observations.
confidence (float) : Confidence level .
precise (bool) : Double precision (true) or single precision (false).
Returns: CI for the linear X coordinate
- - -
CURVE FITTING
An overloaded function that helps transform values between spaces. The primary function uses quantiles, and the overloads wrap the primary function to make working with LogNorm more direct.
fit(x, a, b)
Transforms X coordinate between spaces A and B.
Parameters:
x (float) : Linear X coordinate from space A .
a (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
b (LogNorm | Quantile | array) : LogNorm, Quantile, or float array.
Returns: Adjusted X coordinate
- - -
EXPORTED HELPERS
Small utilities to simplify extensibility.
z_score(ln, x)
Converts a linear X coordinate into a Z Score.
Parameters:
ln (LogNorm) : Object of log space parameters.
x (float) : Linear X coordinate.
Returns: Between -∞ and +∞
x_coord(ln, z)
Converts a Z Score into a linear X coordinate.
Parameters:
ln (LogNorm) : Object of log space parameters.
z (float) : Standard normal Z Score.
Returns: Between 0 and ∞
iget(arr, index)
Gets an interpolated value of a pseudo -element (fictional element between real array elements). Useful for quantile mapping.
Parameters:
arr (array) : Float array object.
index (float) : Index of the pseudo element.
Returns: Interpolated value of the arrays pseudo element.

Min_Position_Size_ALLLibrary "Min_Position_Size_ALL"
getMinPositionSize(symbol_, type_, broker_)
Parameters:
symbol_ (string)
type_ (string)
broker_ (string)

ICOptimizerLibrary "ICOptimizer"
Library for IC-based parameter optimization
findOptimalParam(testParams, icValues, currentParam, smoothing)
Find optimal parameter from array of IC values
Parameters:
testParams (array) : Array of parameter values being tested
icValues (array) : Array of IC values for each parameter (same size as testParams)
currentParam (float) : Current parameter value (for smoothing)
smoothing (simple float) : Smoothing factor (0-1, e.g., 0.2 means 20% new, 80% old)
Returns: New parameter value, its IC, and array index
adaptiveParamWithStarvation(opt, testParams, icValues, smoothing, starvationThreshold, starvationJumpSize)
Adaptive parameter selection with starvation handling
Parameters:
opt (ICOptimizer) : ICOptimizer object
testParams (array) : Array of parameter values
icValues (array) : Array of IC values for each parameter
smoothing (simple float) : Normal smoothing factor
starvationThreshold (simple int) : Number of updates before triggering starvation mode
starvationJumpSize (simple float) : Jump size when in starvation (as fraction of range)
Returns: Updated parameter and IC
detectAndAdjustDomination(longCount, shortCount, currentLongLevel, currentShortLevel, dominationRatio, jumpSize, minLevel, maxLevel)
Detect signal imbalance and adjust parameters
Parameters:
longCount (int) : Number of long signals in period
shortCount (int) : Number of short signals in period
currentLongLevel (float) : Current long threshold
currentShortLevel (float) : Current short threshold
dominationRatio (simple int) : Ratio threshold (e.g., 4 = 4:1 imbalance)
jumpSize (simple float) : Size of adjustment
minLevel (simple float) : Minimum allowed level
maxLevel (simple float) : Maximum allowed level
Returns:
calcIC(signals, returns, lookback)
Parameters:
signals (float)
returns (float)
lookback (simple int)
classifyIC(currentIC, icWindow, goodPercentile, badPercentile)
Parameters:
currentIC (float)
icWindow (simple int)
goodPercentile (simple int)
badPercentile (simple int)
evaluateSignal(signal, forwardReturn)
Parameters:
signal (float)
forwardReturn (float)
updateOptimizerState(opt, signal, forwardReturn, currentIC, metaICPeriod)
Parameters:
opt (ICOptimizer)
signal (float)
forwardReturn (float)
currentIC (float)
metaICPeriod (simple int)
calcSuccessRate(successful, total)
Parameters:
successful (int)
total (int)
createICStatsTable(opt, paramName, normalSuccess, normalTotal)
Parameters:
opt (ICOptimizer)
paramName (string)
normalSuccess (int)
normalTotal (int)
initOptimizer(initialParam)
Parameters:
initialParam (float)
ICOptimizer
Fields:
currentParam (series float)
currentIC (series float)
metaIC (series float)
totalSignals (series int)
successfulSignals (series int)
goodICSignals (series int)
goodICSuccess (series int)
nonBadICSignals (series int)
nonBadICSuccess (series int)
goodICThreshold (series float)
badICThreshold (series float)
updateCounter (series int)

IC optimiser libLibrary "IC optimiser lib"
Library for IC-based parameter optimization
findOptimalParam(testParams, icValues, currentParam, smoothing)
Find optimal parameter from array of IC values
Parameters:
testParams (array) : Array of parameter values being tested
icValues (array) : Array of IC values for each parameter (same size as testParams)
currentParam (float) : Current parameter value (for smoothing)
smoothing (simple float) : Smoothing factor (0-1, e.g., 0.2 means 20% new, 80% old)
Returns: New parameter value, its IC, and array index
adaptiveParamWithStarvation(opt, testParams, icValues, smoothing, starvationThreshold, starvationJumpSize)
Adaptive parameter selection with starvation handling
Parameters:
opt (ICOptimizer) : ICOptimizer object
testParams (array) : Array of parameter values
icValues (array) : Array of IC values for each parameter
smoothing (simple float) : Normal smoothing factor
starvationThreshold (simple int) : Number of updates before triggering starvation mode
starvationJumpSize (simple float) : Jump size when in starvation (as fraction of range)
Returns: Updated parameter and IC
detectAndAdjustDomination(longCount, shortCount, currentLongLevel, currentShortLevel, dominationRatio, jumpSize, minLevel, maxLevel)
Detect signal imbalance and adjust parameters
Parameters:
longCount (int) : Number of long signals in period
shortCount (int) : Number of short signals in period
currentLongLevel (float) : Current long threshold
currentShortLevel (float) : Current short threshold
dominationRatio (simple int) : Ratio threshold (e.g., 4 = 4:1 imbalance)
jumpSize (simple float) : Size of adjustment
minLevel (simple float) : Minimum allowed level
maxLevel (simple float) : Maximum allowed level
Returns:
calcIC(signals, returns, lookback)
Parameters:
signals (float)
returns (float)
lookback (simple int)
classifyIC(currentIC, icWindow, goodPercentile, badPercentile)
Parameters:
currentIC (float)
icWindow (simple int)
goodPercentile (simple int)
badPercentile (simple int)
evaluateSignal(signal, forwardReturn)
Parameters:
signal (float)
forwardReturn (float)
updateOptimizerState(opt, signal, forwardReturn, currentIC, metaICPeriod)
Parameters:
opt (ICOptimizer)
signal (float)
forwardReturn (float)
currentIC (float)
metaICPeriod (simple int)
calcSuccessRate(successful, total)
Parameters:
successful (int)
total (int)
createICStatsTable(opt, paramName, normalSuccess, normalTotal)
Parameters:
opt (ICOptimizer)
paramName (string)
normalSuccess (int)
normalTotal (int)
initOptimizer(initialParam)
Parameters:
initialParam (float)
ICOptimizer
Fields:
currentParam (series float)
currentIC (series float)
metaIC (series float)
totalSignals (series int)
successfulSignals (series int)
goodICSignals (series int)
goodICSuccess (series int)
nonBadICSignals (series int)
nonBadICSuccess (series int)
goodICThreshold (series float)
badICThreshold (series float)
updateCounter (series int)

LIB_SDz_AucLibrary "LIB_SDz_Auc"
TODO: add library description here
getLineStyle(style)
Parameters:
style (string)

testLibLibrary "testLib"
TODO: add library description here
mySMA(x)
TODO: add function description here
Parameters:
x (int) : TODO: add parameter x description here
Returns: TODO: add what function returns

livremySMATestLibLibrary "livremySMATestLib"
TODO: add library description here
mySMA(x)
TODO: add function description here
Parameters:
x (int) : TODO: add parameter x description here
Returns: TODO: add what function returns

Material Color Palette Library█ OVERVIEW
Unlock a world of color in your Pine Script® projects with the Material Color Palette Library . This library provides a comprehensive and structured color system based on Google's Material Design palette, making it incredibly easy to create visually appealing and professional-looking indicators and strategies.
Forget about guessing hex codes. With this library, you have access to 19 distinct color families, each offering a wide range of shades. Every color can be fine-tuned with saturation, darkness, and opacity levels, giving you precise control over your script's appearance.
To make development even easier, the library includes a visual cheatsheet. Simply add the script to your chart to display a full table of all available colors and their corresponding parameters.
█ KEY FEATURES
Vast Spectrum: 19 distinct color families, from vibrant reds and blues to subtle greys and browns.
Fine-Tuned Control: Each color function accepts parameters for `saturationLevel` (1-13 or 1-9) and `darkLevel` (1-3) to select the perfect shade.
Opacity Parameter: Easily add transparency to any color for fills, backgrounds, or lines.
Quick Access Tones: A simple `tone()` function to grab base colors by name.
Visual Cheatsheet: An on-chart table displays the entire color palette, serving as a handy reference guide during development.
█ HOW TO USE
As a library, this script is meant to be imported into your own indicators or strategies.
1. Import the Library
Add the following line to the top of your script. Remember to replace `YourUsername` with your TradingView username.
import mastertop/ColorPalette/1 as colors
2. Call a Color Function
You can now use any of the exported functions to set colors for your plots, backgrounds, tables, and more.
The primary functions take three arguments: `functionName(saturationLevel, darkLevel, opacity)`
`saturationLevel`: An integer that controls the intensity of the color. Ranges from 1 (lightest) to 13 (most vibrant) for most colors, and 1-9 for `brown`, `grey`, and `blueGrey`.
`darkLevel`: An integer from 1 to 3 (1: light, 2: medium, 3: dark).
`opacity`: An integer from 0 (opaque) to 100 (invisible).
Example Usage:
Let's plot a moving average with a specific shade of teal.
// Import the library
import mastertop/ColorPalette/1 as colors
indicator("My Script with Custom Colors", overlay = true)
// Calculate a moving average
ma = ta.sma(close, 20)
// Plot the MA using a color from the library
// We'll use teal with saturation level 7, dark level 2, and 0% opacity
plot(ma, "MA", color = colors.teal(7, 2, 0), linewidth = 2)
3. Using the `tone()` Function
For quick access to a base color, you can use the `tone()` function.
// Set a red background with 85% transparency
bgcolor(colors.tone('red', 85))
█ VISUAL REFERENCE
To see all available colors at a glance, you can add this library script directly to your chart. It will display a comprehensive table showing every color variant. This makes it easy to pick the exact shade you need without guesswork.
This library is designed for fellow Pine Script® developers to streamline their workflow and enhance the visual quality of their scripts. Enjoy!
UTBotLibrary "UTBot"
is a powerful and flexible trading toolkit implemented in Pine Script. Based on the widely recognized UT Bot strategy originally developed by Yo_adriiiiaan with important enhancements by HPotter, this library provides users with customizable functions for dynamic trailing stop calculations using ATR (Average True Range), trend detection, and signal generation. It enables developers and traders to seamlessly integrate UT Bot logic into their own indicators and strategies without duplicating code.
Key features include:
Accurate ATR-based trailing stop and reversal detection
Multi-timeframe support for enhanced signal reliability
Clean and efficient API for easy integration and customization
Detailed documentation and examples for quick adoption
Open-source and community-friendly, encouraging collaboration and improvements
We sincerely thank Yo_adriiiiaan for the original UT Bot concept and HPotter for valuable improvements that have made this strategy even more robust. This library aims to honor their work by making the UT Bot methodology accessible to Pine Script developers worldwide.
This library is designed for Pine Script programmers looking to leverage the proven UT Bot methodology to build robust trading systems with minimal effort and maximum maintainability.
UTBot(h, l, c, multi, leng)
Parameters:
h (float) - high
l (float) - low
c (float)-close
multi (float)- multi for ATR
leng (int)-length for ATR
Returns:
xATRTS - ATR Based TrailingStop Value
pos - pos==1, long position, pos==-1, shot position
signal - 0 no signal, 1 buy, -1 sell


mt_elliott_coreLibrary "mt_elliott_core"
ewo(maFastLen, maSlowLen, smoothLen)
Parameters:
maFastLen (simple int)
maSlowLen (simple int)
smoothLen (simple int)
mt_phase_num(_len, _minGap)
Parameters:
_len (simple int)
_minGap (simple float)
mt_color_from_phase(_len, _minGap)
Parameters:
_len (simple int)
_minGap (simple float)
mt_phase_progress_pct(_len, _minGap)
Parameters:
_len (simple int)
_minGap (simple float)
anchor_p1_close(len, minGap)
Parameters:
len (simple int)
minGap (simple float)
anchor_p1_pivot(len, minGap)
Parameters:
len (simple int)
minGap (simple float)
row_group_from_ewo(ewoValue, atrValue, strongPct, neutralPct)
Parameters:
ewoValue (float)
atrValue (float)
strongPct (simple float)
neutralPct (simple float)
wave_event_pivot_aligned(ewoSeries, left, right, divTolPct, minBarsGap)
Parameters:
ewoSeries (float)
left (simple int)
right (simple int)
divTolPct (simple float)
minBarsGap (simple int)

