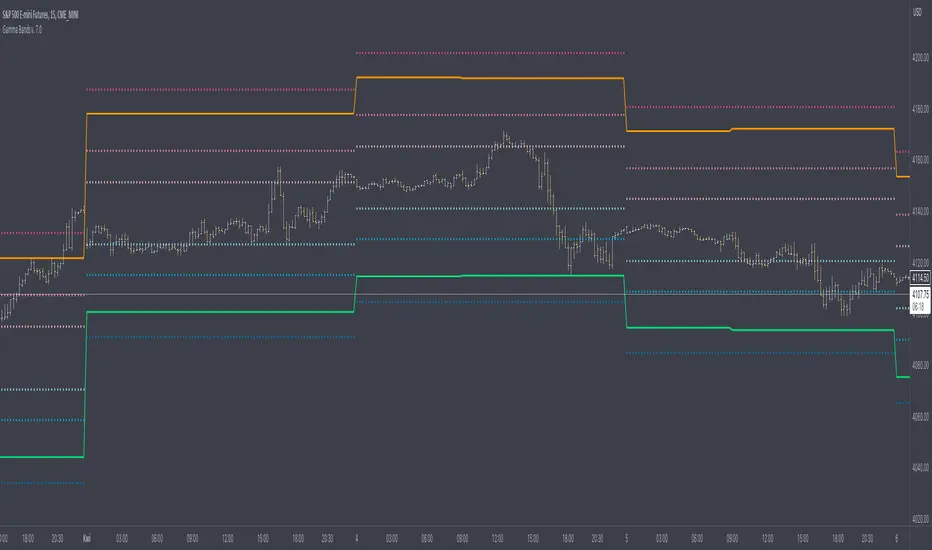
Gamma Bands v. 7.0Gamma Bands are based on previous day data of base intrument, Volatility , Options flow (imported from external source Quandl via TradingView API as TV is not supporting Options as instruments) and few other additional factors to calculate intraday levels. Those levels in correlation with even pure Price Action works like a charm what is confirmed by big orders often placed exactly on those levels on Futures Contracts. We have levels +/- 0.25, 0.5 and 1.0 that are calculated from Pivot Point and are working like Support and Resistance. Higher the number of Gamma, stronger the level. Passing Gamma +1/-1 would be good entry point for trades as almost everytime it is equal to Trend Day. Levels are calculated by Machine Learning algorithm written in Python which downloads data from Options and Darkpool markets, process and calculate levels, export to Quandl and then in PineScript I import the data to indicator. Levels are refreshed each day and are valid for particular trading day.
There's possibility also to enable display of Initial Balance range (High and Low range of bars/candles from 1st hour of regular cash session). Breaking one of extremes of Initial Balance is very often driving sentiment for rest of the session.
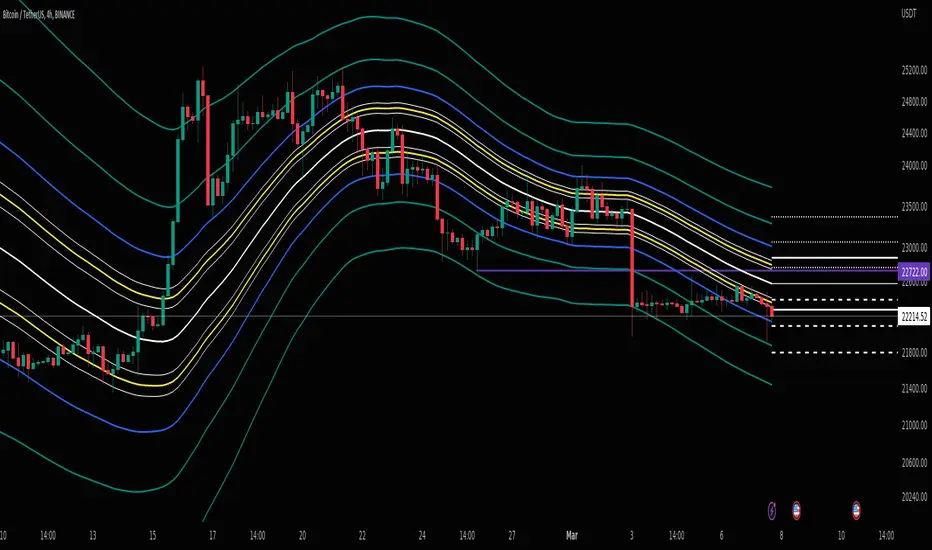
Volatility Reversal Levels
They're calculated taking into account Options flow imported to TV (Strikes, Call/Put types & Expiration dates) in combination with Volatility, Volume flow. Based on that we calculate on daily basis Significant Close level and "Stop and Reversal level".
Very often reaching area close to those levels either trigger immediate reversal of previous trend or at least push price into consolidation range.
Forecast
[TTI] ToS MarketForecast Indicator––––HISTORY & CREDITS 🏦
The ThinkorSwim Market Forecast indicator is an adaptation of the Market Forecast indicator originally created for the ThinkorSwim trading platform. This version has been adapted for use in TradingView, replicating the functionality of the original indicator to assist traders in their market analysis.
––––WHAT IT DOES 💡
The ThinkorSwim Market Forecast is a technical indicator designed to identify potential buying and selling opportunities based on market analysis techniques applied to multiple timeframes. It consists of three plots: Momentum (red line), NearTerm (blue line), and Intermediate (green line). These plots tend to cycle on daily, weekly, and monthly basis, respectively. The indicator also includes static lines representing the top, bottom, and reversal zones.
Calculations:
The ThinkorSwim Market Forecast indicator is a technical analysis tool that calculates three separate lines – Momentum, NearTerm, and Intermediate – to help traders identify potential buying and selling opportunities. The calculations are based on market data from multiple timeframes and involve measuring price movements in relation to their recent high and low values. The indicator highlights areas of potential reversals in the upper and lower zones, allowing traders to make more informed decisions on when to enter or exit a position.
––––HOW TO USE IT 🔧
To use the ThinkorSwim Market Forecast indicator, look for simultaneous reversals of the three lines in the upper or lower zones. A Buy signal is generated when all three lines go through a reversal at the same (or almost the same) time in the bottom zone (green cloud). Conversely, a simultaneous reversal in the upper zone (red cloud) suggests a Sell signal.
To add this indicator to your TradingView chart, copy the provided script and paste it into the Pine editor. Save and add the script to your chart, and the indicator will be displayed, allowing you to analyze the market based on the Momentum, NearTerm, and Intermediate lines, as well as the upper and lower reversal zones.

Trend forecasting by c00l75----------- ITALIANO -----------
Questo codice è uno script di previsione del trend creato solo a scopo didattico. Utilizza una media mobile esponenziale (EMA) e una media mobile di Hull (HMA) per calcolare il trend attuale e prevedere il trend futuro. Il codice utilizza anche una regressione lineare per calcolare il trend attuale e un fattore di smorzamento per regolare l’effetto della regressione lineare sulla previsione del trend. Infine il codice disegna due linee tratteggiate per mostrare la previsione del trend per i periodi futuri specificati dall’utente. Se ti piace l'idea mettimi un boost e lascia un commento!
----------- ENGLISH -----------
This code is a trend forecasting script created for educational purposes only. It uses an exponential moving average (EMA) and a Hull moving average (HMA) to calculate the current trend and forecast the future trend. The code also uses a linear regression to calculate the current trend and a damping factor to adjust the effect of the linear regression on the trend prediction. Finally, the code draws two dashed lines to show the trend prediction for future periods specified by the user. If you like the idea please put a boost and leave a comment!
Volume Forecasting [LuxAlgo]The Volume Forecasting indicator provides a forecast of volume by capturing and extrapolating periodic fluctuations. Historical forecasts are also provided to compare the method against volume at time t .
This script will not work on tickers that do not have volume data.
🔶 SETTINGS
Median Memory: Number of days used to compute the median and first/third quartiles.
Forecast Window: Number of bars forecasted in the future.
Auto Forecast Window: Set the forecast window so that the forecast length completes an interval.
🔶 USAGE
The periodic nature of volume on certain securities allows users to more easily forecast using historical volume. The forecast can highlight intervals where volume tends to be more important, that is where most trading activity takes place.
More pronounced periodicity will tend to return more accurate forecasts.
The historical forecast can also highlight intervals where high/low volume is not expected.
The interquartile range is also highlighted, giving an area where we can expect the volume to lie.
🔶 DETAILS
This forecasting method is similar to the time series decomposition method used to obtain the seasonal component.
We first segment the chart over equidistant intervals. Each interval is delimited by a change in the daily timeframe.
To forecast volume at time t+1 we see where the current bar lies in the interval, if the bar is the 78th in interval then the forecast on the next bar is made by taking the median of the 79th bar over N intervals, where N is the median memory.
This method ensures capturing the periodic fluctuation of volume.

Momentum Covariance Oscillator by TenozenWell, guess what? A new indicator is here! Again it's a coincidence, as I experiment with my formula. So far it's less noisy than Autoregressive Covariance Oscillator, so possibly this one is better. The formula is much simpler, care me to explain.
___________________________________________________________________________________________________
Yt = close - previous average
Val = Yt/close
___________________________________________________________________________________________________
Welp that's the formula lol. Funny thing is that it's so simple, but it's good! What matters is the use of it haha.
So how to use this Oscillator? If the value is above 0, we expect a bullish response, if the value is below 0 we expect a bearish response. That simple. Ciao.
(Any questions and suggestions? feel free to comment!)

Autoregressive Covariance Oscillator by TenozenWell to be honest I don't know what to name this indicator lol. But anyway, here is my another original work! Gonna give some background of why I create this indicator, it's all pretty much a coincidence when I'm learning about time series analysis.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
Well, the formula of Auto-covariance is:
E{(X(t)-(t) * (X(t-s)-(t-s))}= Y_s
But I don't multiply both values but rather subtract them:
E{(X(t)-(t) - (X(t-s)-(t-s))}= Y_s?
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
For arm_vald, the equation is as follows:
arm_vald = val_mu + mu_plus_lsm + et
val_mu --> mean of time series
mu_plus_lsm --> val_mu + LSM
et --> error term
As you can see, val_mu^2. I did this so the oscillator is much smoother.
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
After I get the value, I normalize them:
aco = Y_s? / arm_vald
So by this calculation, I get something like an oscillator!
(more details in the code)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
So how to use this indicator? It's so easy! If the value is above 0, we gonna expect a bullish response, if the value is below 0, we gonna expect a bearish response; that simple. Be aware that you should wait for the price to be closed before executing a trade.
Well, try it out! So far this is the most powerful indicator that I've created, hope it's useful. Ciao.
(more updates for the indicator if needed)

Fed Projected Interest RatesThis script shows you the current interest rates by the FED (see ZQ symbol nearest expiration)
and the next expirations (see ZQ further expiration dates).
It is important to keep your expiration and descriptions up to date, to do that to the indicator inputs and change as you please.

Trendgetter: Trend Detection, Regime Change, Bias Filter by [CR]Trendgetter: Trend Detection, Regime Change, Bias Filter by Cryptorhythms
“If you are not a trend setter, at least be able to exploit the ones you see.”
― Jeffrey Fry
Intro
Cryptorhythms back again with a members only indicator for trend capture this time! Trendgetter is not crypto specific and can be applied to a variety of timeframes, markets, and tickers. Its meant to be a general purpose trading aid and bias filter, providing reliable trend, bias and regime change information.
Introduction
This indicator relies upon various methods related to probabilities/statistics, digital signal processing and data science to predict optimal fair local price given any financial time series data. The goal was to create a tool that isolates trends and captures their bias, making it easier to follow a noisy market. The focus is making high hit rate uncorrelated returns to your base market. The way in which this indicator is constructed is not based upon any previous public work, and was researched and refined over a period of 6 months of trading and testing based on my own personal trading experiences and observations of the market. I use novel techniques I developed in house to denoise the data and determine a local fair price.
Description
The parameters in this indicator are mostly fixed and do not lend themselves to overfitting. So when you find good settings, its probably legit and not a false positive. They were pre-determined based on my own testing and research to handle almost all possible combinations of price action for determining trends. By fixing some parameters, you automatically reduce the chances of overfitting to historical data. The pre determined levels were carefully chosen after many options were considered.
Not just a bias filtooor, fair price predictooor and regime change detectoooor though! TG also provides a price envelope feature which shows a likely fair price range that price will distribute itself upon. Above or below the envelope indicates the presence of a very strong trend . Within the envelope indicates consolidation , but still conforming to the bias. TG then uses a statistics-based approach to display a likely range that price could potentially travel over the near term which we called a price envelope.
An additional option provides background coloration when there is the potential for a regime change on the trend bias. This can be used as a feature to help you manage your trades risk. This is simply measured by an internal (non exposed) script value returning to a mean which triggers the color to appear.
Further Explanation of Settings
-Timeframe : Change the timeframe the indicator is calculated on allowing you to for instance use the 15m Trendgetter output while remaining on the 5 minute chart.
-Trend Capture : This is the "type" of trend you are trying to follow. The different options will attempt to find the trends at various levels of noise cancellation within the lookback period you specify. "Reactive" means it will quickly change its bias and capture smaller trends. "Slow" means it will filter more noise and capture larger trends. "Adaptive" is completely in its own class of behavior and was my attempt to mix both a slow and reactive profile into one setting, it uses a few market metrics like volume and volatility to adjust parameters on the fly.
-Sample Length : Bars to consider in the calculation. Using large numbers here is not going to help, but rather hurt your results. Generally 10-100 is the range you should use for the best results. The exact value will depend on the timeframe, volatility and market/asset you are trading, and you should experiment to find it. (There is no "one size fits all" for potential trading situations)
-Source : Data series used for calculation. I recommend hlcc4 or hl2 or hlc3 instead of just "close." This will help to pre process a noisy data series for the rest of the algo.
-Certainty Level : This setting effects how easily the indicator will confirm a new trend and change its bias. " Reactive" does just as it says and will confirm new regimes faster, but can also lead to false signals or "flip flop" in certain types of price action. "Slow" will change biases less frequently or in conjunction with large moves - but this level of certainty requires the sacrifice of reactivity meaning its a bit laggy (but thats ok when you are following a larger trend). "Medium" is as you would expect the middle ground between reactive and slow. Lastly "Adaptive" tends to fall between reactive and medium in its behavior typically, but it will somewhat adjust itself to suit the variability of market conditions.
-Price Envelope :
-----My own personally created price distribution spread (not monte carlo based)
-----Above or below the envelope indicates the presence of a very strong trend. You should not be fading a trend when its in this position!
-----Within the envelope indicates consolidation, but still conforming to the bias.
User Requests :
Of course we also listen to the needs of our members and added these features upon request.
-Added dark mode and light mode themes.
----Dark Mode is for dark/black charts and uses lighter colorations
----Light mode is for light/white charts and uses darker colorations
-More updates to display and color selection options such as background colors and fill colors.
סקריפט בתשלום
BB Mod + ForecastThis is a combination of two previous indicators; ALMA stdev band with fibs and Vector MACD.
Bollinger Band Mod fits the standard deviation on both sides of the center moving average ( ALMA +/- stdev / 2 ) and calculates Fibonacci ratios from stdev on both sides.
It is more averaging and more responsive at the same time compared to Bollinger Band.
Forecast is calculated from difference between origin ma ( ALMA from hl2 ) and six different period Hull moving averages averaged together and added to the center ma on both sides.
Fibonacci levels for 0.618 1.618 and 2.618 are added.
The dashed lines point towards the trend. Gives you a better idea of the current trend and momentum in the band.
Faytterro Oscillatorwhat is Faytterro oscillator?
An oscillator that perfectly identifies overbought and oversold zones.
what it does?
this places the price between 0 and 100 perfectly but with a little delay. To eliminate this delay, it predicts the price to come, and the indicator becomes clearer as the probability of its prediction increases.
how it does it?
This indicator is obtained with "faytterro bands", another indicator I designed. For more information about faytterro bands:
A kind of stochastic function is applied to the faytterro bands indicator, and then another transformation formula that I have designed and explained in detail in the link above is applied. These formulas are also applied again to calculate the prediction parts.
how to use it?
Use this indicator to see past overbought and oversold zones and to see future ones.
The input named source is used to change the source of the indicator.
The length serves to change the signal frequency of the indicator.

Hurst Spectral Analysis Oscillator"It is a true fact that any given time history of any event (including the price history of a stock) can always be considered as reproducible to any desired degree of accuracy by the process of algebraically summing a particular series of sine waves. This is intuitively evident if you start with a number of sine waves of differing frequencies, amplitudes, and phases, and then sum them up to get a new and more complex waveform." (Spectral Analysis chapter of J M Hurst's book, Profit Magic )
Background: A band-pass filter or bandpass filter is a device that passes frequencies within a certain range and rejects (attenuates) frequencies outside that range. Bandpass filters are widely used in wireless transmitters and receivers. Well-designed bandpass filters (having the optimum bandwidth) maximize the number of signal transmitters that can exist in a system while minimizing the interference or competition among signals. Outside of electronics and signal processing, other examples of the use of bandpass filters include atmospheric sciences, neuroscience, astronomy, economics, and finance.
About the indicator: This indicator will accept float/decimal length inputs to display a spectrum of 11 bandpass filters. The trader can select a single bandpass for analysis that includes future high/low predictions. The trader can also select which bandpasses contribute to a composite model of expected price action.
10 Statements to describe the 5 elements of Hurst's price-motion model:
Random events account for only 2% of the price change of the overall market and of individual issues.
National and world historical events influence the market to a negligible degree.
Foreseeable fundamental events account for about 75% of all price motion. The effect is smooth and slow changing.
Unforeseeable fundamental events influence price motion. They occur relatively seldom, but the effect can be large and must be guarded against.
Approximately 23% of all price motion is cyclic in nature and semi-predictable (basis of the "cyclic model").
Cyclicality in price motion consists of the sum of a number of (non-ideal) periodic cyclic "waves" or "fluctuations" (summation principle).
Summed cyclicality is a common factor among all stocks (commonality principle).
Cyclic component magnitude and duration fluctuate slowly with the passage of time. In the course of such fluctuations, the greater the magnitude, the longer the duration and vice-versa (variation principle).
Principle of nominality: an element of commonality from which variation is expected.
The greater the nominal duration of a cyclic component, the larger the nominal magnitude (principle of proportionality).
Shoutouts & Credits for all the raw code, helpful information, ideas & collaboration, conversations together, introductions, indicator feedback, and genuine/selfless help:
🏆 @TerryPascoe
🏅 DavidF at Sigma-L, and @HPotter
👏 @Saviolis, parisboy, and @upslidedown

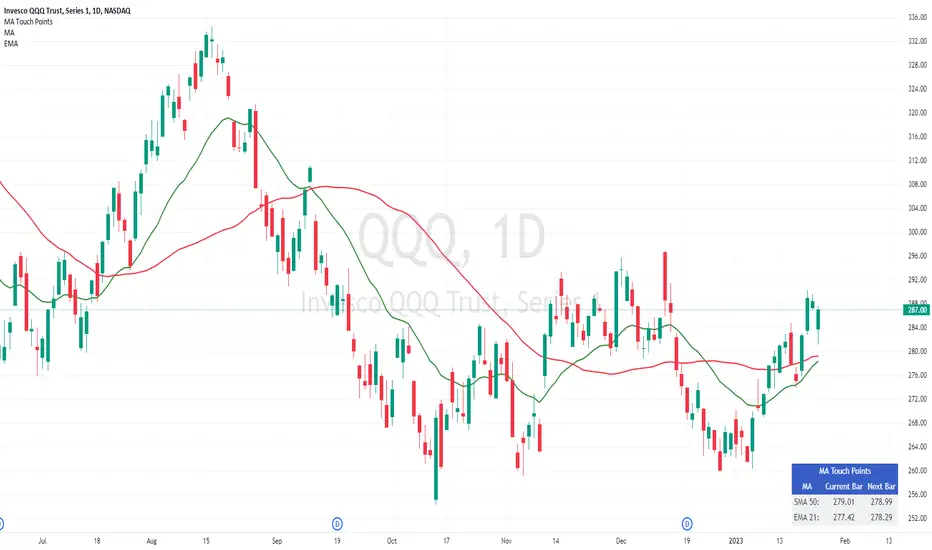
Moving Average Touch PointsThis tool allows you to know at what price a security will touch its moving average today or tomorrow. This may sound simple, but today's action will influence the final value of the average itself, causing it to 'move' during the live session. This is problematic for people trying to use an average to place orders - especially with shorter-term averages. This tool shows the exact point mathematically where the price will equal its average on the current bar and the next bar. This allows you to plan precisely during a live trading session or in the evening for tomorrow's trading session.
The tool works on all time frames for people seeking to use it on intraday or weekly charts.
Acknowledgment
Thank you to @JohnMuchow for coding my formulas.
Wavechart v2 ##Wave Chart v2##
For analyzing Neo-wave theory
Plot the market's highs and lows in real-time order.
Then connect the highs and lows
with a diagonal line. Next, the last plot of one day (or bar) is connected with a straight line to the
first plot of the next day (or bar).
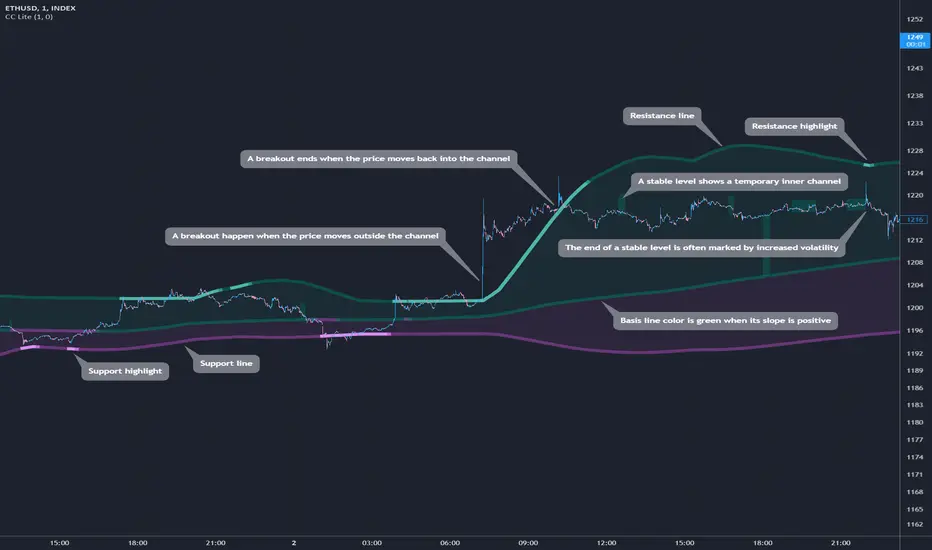
Cosmic Channel LiteCosmic Channel Lite ( CC Lite) draws dynamic non-repainting trendlines and helps
⭐ know when a breakout is about to begin
⭐ predict the position and timing of the next swing reversal
⭐ predict sudden changes in volatility
⭐ recognize whether the price is in bearish or bullish territory
👀 HOW IT WORKS
Cosmic Channel Lite draws a dynamic channel consisting of a support line, basis line and resistance line. These are calculated by applying the Reduced Median Method to groups of moving averages of different type over several periods each, effectively taking 20 data points and reducing them to 3. In between, 6 internal levels are left to give context inside the channel with stable levels, the extremes of which help highlight the SR lines (see chart). The basis line color is determined by its smoothed angle with positive angles in green and negative in purple. The aim of this indicator is to provide a consistent and generic price context that works out-of-the-box and accordingly the settings have been stripped to the bare minimum with no need to continually adjust them.
📗 HOW TO USE IT
The Cosmic Channel Lite plots are meant to be used as a guide for entering and exiting positions and setting stop-loss and take profit levels. The indicator is deemed effective for any particular timeframe as long as the price stays within the maximum bounds of the indicator's plots. For this reason it is recommended to use Cosmic Channel Lite in a multi-chart layout where each chart has a different timeframe. The 5 primary strategies are:
long when the price reverses off of the support line and short when the price reverses off of the resistance line
long when the support line is highlighted and short when the resistance line is highlighted
long when the price breaks above the resistance line and short when the price breaks below the support line
long when the price moves above the basis line after being below it for a prolonged period and visa-versa (short when the price moves below the basis line)
long/short in the direction the price takes after a stable level ends
🔔 SMART ALERTS
Get notified at the most critical times by settings just one alert. Simply select CC Lite and Any alert() function call as the conditions when creating an alert and you will be tipped-off on bar-close as follows:
R─ (resistance line is highlighted)
S─ (support line is highlighted)
For example, an alert such as CC Lite 6h R─ would mean that during the last 6-hour bar the resistance line has been highlighted. The highlight lasts at least 15 bars from the first highlight bar regardless of price action.
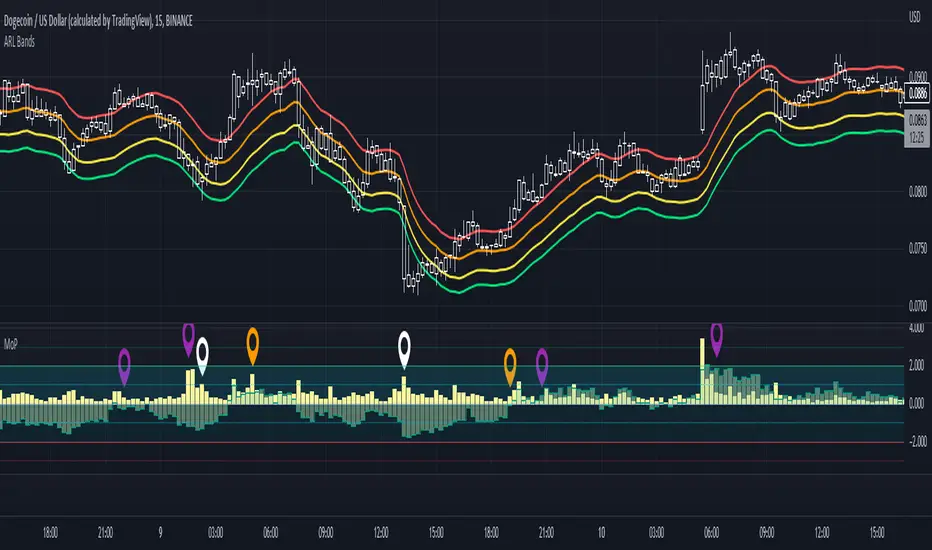
Movement Polarization (MoP)This shows the negative or positive charge of price movement and volume .
The "Polarization" shows how much negativity or positivity the movement of the price and volume have.
IMPORTANT:
Use with crypto currencies only is highly recommended.
If the volume in a currency is not visible, adjust the "Factor" number higher in the "Inputs" tab.
Adjust it until there is a balance between the vertical spread of the volume and polarization.
There will be a noticeable jump in the scale of the indicator if it is set too high.
The "Factor" is scaled at a baseline for SHIB prices. Any lower price scales than SHIB's will not show the volume .
Version:
This is a forked codebase to conserve the functionality of "RSI TV". The "RSI TV" focuses only on the RSI trend, this focuses on price and volume movement.
As such, there is no need for the MA of the RSI. Also, the TV Line from the "RSI TV" is used to show polarization of movement in this context.
The Trend Veracity line from the "RSI TV" has a broad scope in verifying different, particular trends, not just the RSI trend.
The RSI, volume, and polarization are all conveniently placed within the same scale to facilitate longer-term trading with price action. See also: "RSI TV" .
How this indicator is original; what it does, and how it does it:
This indicator has an original, unique ability to give the volume a further-projecting forecast.
The MoP does this by placing the volume on a vertical scale. It then compares it to a polarization level.
This gives 3 reference points: 1) Past data of volume, 2) volume vertical thresholds, and 3) polarization levels.
The volume by itself has no reference but its own past data. This gives a short-sighted forecast.
How to use it:
Useful with a trend finding indicator and price-action trading. See notes in picture above (scroll chart left to see first note).
Extra indicator shown in chart is an adjusted "ARL Bands" .
1) A condensing of volume and polarization usually means that an uptrend will soon turn.
2) A widening of volume and polarization usually means that a downtrend will soon turn.
3) A weak uptrend is indicated when volume falls while low, positive polarization also falls.
4) A growing uptrend is indicated when volume and positive polarization grow together.
5) Overlapping volume and positive polarization usually signifies oncoming peaks.
DB Change Forecast ProDB Change Forecast Pro
What does the indicator do?
The DB Change Forecast Pro is a unique indicator that uses price change on HLC3 to detect buy and sell periods along with plotting a linear regression price channel with oversold and undersold zones. It also has a linear regression change forecast mode to optionally project market direction.
Change is calculated by taking a two-bar change of HLC3 and dividing that by the price or, optionally, a fixed divisor.
A fast-moving change cloud is then calculated and displayed as the "regular version" plot (shown in light gray). When the cloud bottom is above low, a buy zone is detected. When the cloud top is below the high, a sell zone is detected.
The linear regression price channel is calculated similarly but using a much slower change rate. The linear regression price channel shows reasonable high, low and HLC3 ranges. At the bar's opening, the channel will be more compact and come fairly accurate about 1/4 into the bar timeframe.
The change forecasted price is projected on the right side of the current bar to indicate the current timeframe direction. Please note this forecasting feature is shown in orange when it's early in the timeframe and gray when the timeframe is more likely to produce an accurate direction forecast for the upcoming bar.
You can use these projected dashed lines to see possible market movements for the Current bar and possible market direction for the next bar. Kindly note these projects change; they should be used to understand possible extreme highs/lows for the current bar or market direction.
The indicator includes an optional change forecast projection feature hidden by default. It will project the market forecast channel with an offset of 1. The forecast is defaulted to an offset of 1 to show market direction. However, you can modify to zero the offset to show the current bar forecast and forecast history.
How should this indicator be used?
First, very important,
1. Settings > Set Symbol to Desired
2. Settings > Set High Timeframe to "Chart"
3. Settings > Ensure "Use price as divisor" is checked.
It's recommended to use this indicator in higher timeframes. Buy and sell signals are displayed in real-time. However, waiting until 1/4 to 1/2 into the current bar is recommended before taking action, and change can happen.
The buy/sell signals (zones) provide recommendations on playing a long vs. a short. When in a buy sone, only play longs. When in a sell zone, only play shorts.
Then use the linear regression price channel oversold and undersold zones to optionally open and close positions within the buy/sell zones.
For example, consider opening a long in a buy zone when the linear regression price channel shows undersold. Then consider closing the long when the price moves into the linear regression oversold or higher. Then repeat as long as it's in the buy zone. Then vice versa for sell zones and shorting.
At basic design, buy in the buy zone, sell or short in the sell zone. If you are up for higher trading frequencies, use the linear regression price channel as described in the example above.
Please note, as, with all indicators, you may need to adjust to fit the indicator to your symbol and desired timeframe.
This is only an example of use. Please use this indicator as your own risk and after doing your due diligence.
Does the indicator include any alerts?
Yes,
"DB CFHLC3: Signal BUY" - Is triggered when a buy signal is fired.
"DB CFHLC3: Signal SELL" - Is triggered when a sell signal is fired.
"DB CFHLC3: Zone BUY" - Is triggered when a buy zone is detected.
"DB CFHLC3: Zeon SELL" - Is triggered when a sell zone is detected.
"DB CFHLC3: Oversold SELL" - Is triggered when the price exceeds the oversold level.
"DB CFHLC3: Undersold BUY" - Is triggered when the price goes below the undersold level.
Any other tips?
Once you have configured the indicator for your symbol and chart timeframe. Meaning the plots are displayed over the price. Check out larger timeframes such as W, 2W, 3W, 4W, M, and 4M. It works wonderfully for showing market lows and highs for long-term investing too!
Another, tip is to combine it with your favorite indicator, such as TTM Squeeze or MACD for confirmation purposes. You may be surprised how fast the indicator shows market direction changes on higher timeframes.
You can just as easily use a high timeframe such as D, 2D, or 3D for day trading due to how the linear price channel works.
Why am I not selling this indicator?
I would like to bless the TradingView community, and I enjoy publishing custom indicators.
If you enjoy this indicator, please consider leaving a thumbs up or a comment for others to know about your experience or recommendations.
Enjoy!
Fourier Spectrometer of Price w/ Extrapolation Forecast [Loxx]Fourier Spectrometer of Price w/ Extrapolation Forecast is a forecasting indicator that forecasts the sinusoidal frequency of input price. This method uses Linear Regression with a Fast Fourier Transform function for the forecast and is different from previous forecasting methods I've posted. Dotted lines are the forecast frequencies. You can change the UI colors and line widths. This comes with 8 frequencies out of the box. Instead of drawing sinusoidal manually on your charts, you can use this instead. This will render better results than eyeballing the Sine Wave that folks use for trading. this is the real math that automates that process.
Each signal line can be shown as a linear superposition of periodic (sinusoidal) components with different periods (frequencies) and amplitudes. Roughly, the indicator shows those components. It strongly depends on the probing window and changes (recalculates) after each tick; e.g., you can see the set of frequencies showing whether the signal is fast or slow-changing, etc. Sometimes only a small number of leading / strongest components (e.g., 3) can extrapolate the signal quite well.
Related Indicators
Fourier Extrapolator of 'Caterpillar' SSA of Price
Real-Fast Fourier Transform of Price w/ Linear Regression
Fourier Extrapolator of Price w/ Projection Forecast
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
***The period parameter doesn't correspond to how many bars back the drawing begins. Lines re rendered according to skipping mechanism due to TradingView limitations.
Price & Time SquaredHi Traders..
This is one of Gann's trading method, called Price & Time Squared. When price & time meets, price will reverse."
as you see, those lines (past & future) represent the forecast of 'potential' swing (swing high/low or turning up/ down)
here are some examples:
Weekly
Daily
H1
M30
M15
M5
How to trade (very simple):
- if the trend is down and tomorrow there is a 'Price & Time Squared Line', we can prepare to take long position (combine with your favorite price action)
- if the trend is up and tomorrow there is a 'Price & Time Squared Line', we can prepare to take short position (combine with your favorite price action)
- stop loss if the chart makes Lower Low (for Long Position)
- stop loss if the chart makes Higher High (for Short Position)
you can use those lines as guidance in your trading (just like Traffic Light)
PS:
-if you see 2 or 3 lines close together, or 2 or 3 lines stack in 1 line (cluster), it means the Time Factor is 'Strong'
the stronger the cluster the stronger the Time Factor
- due to time delay & time lag, the turning can be +/- 1 bar
- PM for trial access
“Time is the most important factor of all and not until sufficient time has expired does any big move start up or down. The time factor will overbalance both space and volume. When time is up, space movement will start and large volume will begin, either up or down.

Fourier Extrapolator of 'Caterpillar' SSA of Price [Loxx]Fourier Extrapolator of 'Caterpillar' SSA of Price is a forecasting indicator that applies Singular Spectrum Analysis to input price and then injects that transformed value into the Quinn-Fernandes Fourier Transform algorithm to generate a price forecast. The indicator plots two curves: the green/red curve indicates modeled past values and the yellow/fuchsia dotted curve indicates the future extrapolated values.
What is the Fourier Transform Extrapolator of price?
Fourier Extrapolator of Price is a multi-harmonic (or multi-tone) trigonometric model of a price series xi, i=1..n, is given by:
xi = m + Sum( a*Cos(w*i) + b*Sin(w*i), h=1..H )
Where:
xi - past price at i-th bar, total n past prices;
m - bias;
a and b - scaling coefficients of harmonics;
w - frequency of a harmonic ;
h - harmonic number;
H - total number of fitted harmonics.
Fitting this model means finding m, a, b, and w that make the modeled values to be close to real values. Finding the harmonic frequencies w is the most difficult part of fitting a trigonometric model. In the case of a Fourier series, these frequencies are set at 2*pi*h/n. But, the Fourier series extrapolation means simply repeating the n past prices into the future.
Quinn-Fernandes algorithm find sthe harmonic frequencies. It fits harmonics of the trigonometric series one by one until the specified total number of harmonics H is reached. After fitting a new harmonic , the coded algorithm computes the residue between the updated model and the real values and fits a new harmonic to the residue.
see here: A Fast Efficient Technique for the Estimation of Frequency , B. G. Quinn and J. M. Fernandes, Biometrika, Vol. 78, No. 3 (Sep., 1991), pp . 489-497 (9 pages) Published By: Oxford University Press
Fourier Transform Extrapolator of Price inputs are as follows:
npast - number of past bars, to which trigonometric series is fitted;
nharm - total number of harmonics in model;
frqtol - tolerance of frequency calculations.
What is Singular Spectrum Analysis ( SSA )?
Singular spectrum analysis ( SSA ) is a technique of time series analysis and forecasting. It combines elements of classical time series analysis, multivariate statistics, multivariate geometry, dynamical systems and signal processing. SSA aims at decomposing the original series into a sum of a small number of interpretable components such as a slowly varying trend, oscillatory components and a ‘structureless’ noise. It is based on the singular value decomposition ( SVD ) of a specific matrix constructed upon the time series. Neither a parametric model nor stationarity-type conditions have to be assumed for the time series. This makes SSA a model-free method and hence enables SSA to have a very wide range of applicability.
For our purposes here, we are only concerned with the "Caterpillar" SSA . This methodology was developed in the former Soviet Union independently (the ‘iron curtain effect’) of the mainstream SSA . The main difference between the main-stream SSA and the "Caterpillar" SSA is not in the algorithmic details but rather in the assumptions and in the emphasis in the study of SSA properties. To apply the mainstream SSA , one often needs to assume some kind of stationarity of the time series and think in terms of the "signal plus noise" model (where the noise is often assumed to be ‘red’). In the "Caterpillar" SSA , the main methodological stress is on separability (of one component of the series from another one) and neither the assumption of stationarity nor the model in the form "signal plus noise" are required.
"Caterpillar" SSA
The basic "Caterpillar" SSA algorithm for analyzing one-dimensional time series consists of:
Transformation of the one-dimensional time series to the trajectory matrix by means of a delay procedure (this gives the name to the whole technique);
Singular Value Decomposition of the trajectory matrix;
Reconstruction of the original time series based on a number of selected eigenvectors.
This decomposition initializes forecasting procedures for both the original time series and its components. The method can be naturally extended to multidimensional time series and to image processing.
The method is a powerful and useful tool of time series analysis in meteorology, hydrology, geophysics, climatology and, according to our experience, in economics, biology, physics, medicine and other sciences; that is, where short and long, one-dimensional and multidimensional, stationary and non-stationary, almost deterministic and noisy time series are to be analyzed.
"Caterpillar" SSA inputs are as follows:
lag - How much lag to introduce into the SSA algorithm, the higher this number the slower the process and smoother the signal
ncomp - Number of Computations or cycles of of the SSA algorithm; the higher the slower
ssapernorm - SSA Period Normalization
numbars =- number of past bars, to which SSA is fitted
Included:
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
Related Fourier Transform Indicators
Real-Fast Fourier Transform of Price w/ Linear Regression
Fourier Extrapolator of Variety RSI w/ Bollinger Bands
Fourier Extrapolator of Price w/ Projection Forecast
Related Projection Forecast Indicators
Itakura-Saito Autoregressive Extrapolation of Price
Helme-Nikias Weighted Burg AR-SE Extra. of Price
Related SSA Indicators
End-pointed SSA of FDASMA
End-pointed SSA of Williams %R
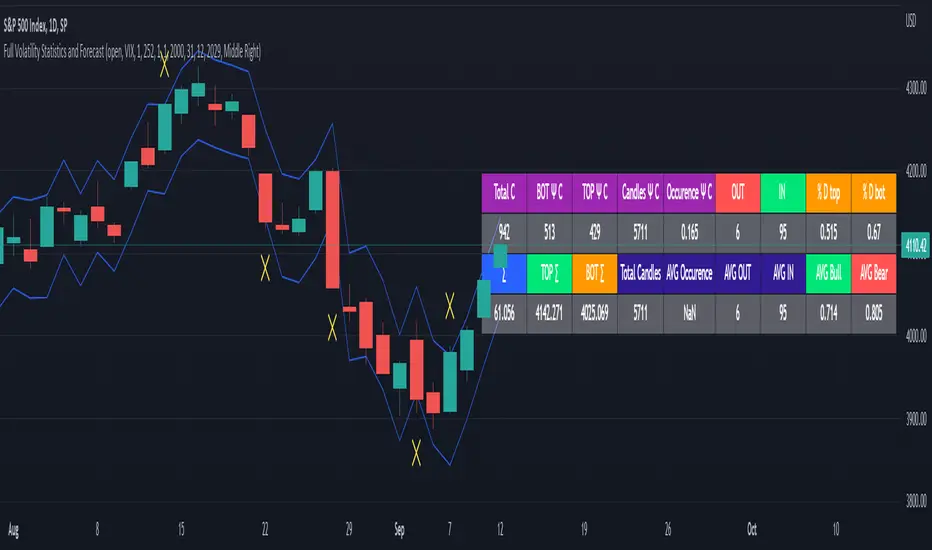
Full Volatility Statistics and Forecast
This is a tool designed to translate the data from the expected volatility of different assets, such as for example VIX, which measures the volatility of SP500 index.
Once get the data from the volatility asset we want to measure(for this test I have used VIX), we are going to translate it the required timeframe expected move by dividing the initial value into :
252 = if we want to use the daily timeframe, since there are ~252 aproximative daily trading days
52 = if we want to use the weekly timeframe, since there 52 trading weeks in a year
12 = if we want to use the monthly timeframe, since there are 12 months in a year
For this example I have used 252 with the daily timeframe.
In this scenario, we can see that we had 5711 total cnadles which we analysed, and in this case, we had 942 crosses, where the daily movement ended up either above or below the channel made from the opening daily candle value + expected movement from the volatility, giving as a total of 16.5% of occurances that volatility was higher than expected, and in 83.5% of the times, we can see that the price stayed within our channel.
At the same time, we can see that we had 6 max losses in a row ( OUT) AND 95 max wins in a row (IN), and at the same time in those moments when the volatility crosses happen we had a 0.51% avg movements when the top crossed happened, and 0.67% avg movements when the bot happened.
Lastly on the second part of the panel, we had E which means the expected movement of today, for example it has 61.056$ , so lets say price opened on 4083, our top is 4083 + 61 and our bot is 4083 - 61 ( giving us the daily channel). At continuation we can see that overall the avg bull candle os 0.714% and avg bear candle was 0.805% .
I hope this tool will help you with your future analysis and trades !
If you have any questions please let me know !
vol_coneDraws a volatility cone on the chart, using the contract's realized volatility (rv). The inputs are:
- window: the number of past periods to use for computing the realized volatility. VIX uses 30 calendar days, which is 21 trading days, so 21 is the default.
- stdevs: the number of standard deviations that the cone will cover.
- periods to project: the length of the volatility cone.
- periods per year: the number of periods in a year. for a daily chart, this is 252. for a thirty minute chart on a contract that trades 23 hours a day, this is 23 * 2 * 252 = 11592. for an accurate cone, this input must be set correctly, according to the chart's time frame.
- history: show the lagged projections. in other words, if the cone is set to project 21 periods in the future, the lines drawn show the top and bottom edges of the cone from 23 periods ago.
- rate: the current interest or discount rate. this is used to compute the forward price of the underlying contract. using an accurate forward price allows you to compare the realized volatility projection to the implied volatility projections derived from options prices.
Example settings for a 30 minute chart of a contract that trades 23 hours per day, with 1 standard deviation, a 21 day rv calculation, and half a day projected:
- stdevs: 1
- periods to project: 23
- window: 23 * 2 * 21 = 966
- periods per year: 23 * 2 * 252 = 11592
Additionally, a table is drawn in the upper right hand corner, with several values:
- rv: the contract's current realized volatility.
- rnk: the rv's percentile rank, compared to the rv values on past bars.
- acc: the proportion of times price settled inside, versus outside, the volatility cone, "periods to project" into the future. this should be around 65-70% for most contracts when the cone is set to 1 standard deviation.
- up: the upper bound of the cone for the projection period.
- dn: the lower bound of the cone for the projection period.
Limitations:
- pinescript only seems to be able to draw a limited distance into the future. If you choose too many "periods to project", the cone will start drawing vertically at some limit.
- the cone is not totally smooth owing to the facts a) it is comprised of a limited number of lines and b) each bar does not represent the same amount of time in pinescript, as some cross weekends, session gaps, etc.

NEoWave ChartAn automated wave chart for NEoWave wave analysis. This is an automated wave chart plotter that help you to find the current psychological trend and forecast the next one. This Indicator uses the concept of plotting wave charts as per the NeoWave method invented by Glenn Neely in 1990 in the “Mastering Elliott Wave” book. NEoWave is a advanced version of elliott wave theory, which solve the lots of drawback's and issues' of elliott wave theory.
The Logic and Concept used in Indicator
This indictor uses the logic of plotting wave chart as discussed in “Mastering Elliott Wave” book, According to “Mastering Elliott Wave” book to draw a wave chart draw a line from high to low or low to high in order that they occurred, and this indicator plot the line accurately from high to low or low to high in order they occurred.
Some Important Features
1. This indicator can draw wave chart from 5 Seconds to 5 Year or use any custom timeframe of your choice.
2. Use any timeframe wave chart on any timeframe cash data, like use monthly cash data to draw 2.5 years or 5 years wave chart.
3. Do the easy back testing with easy drag tool.
4. Customize wave chart settings based on your requirement.
5. Wave chart will be plotted on any type of charts like candlestick or bar chart.
6. Custom settings to hide other charts, like you can hide bar or candlestick chart, while using wave analysis.
7. Realtime plotting of wave chart from 5 seconds to 5 year.
Features to be added in future update
1. Show Monowave Counts.
2. Show Complexity levels.
3. Show Price and Time.
4. Show Starting point of patterns.
How to use this wave chart?
1. Use the log scale on wave chart. Use Alt + L to use logarithmic scale on chart.
2. Use log Fibonacci on wave chart, just open the settings of Fibonacci channel and check on "Fib channel based on log scale"
3. Find the correct starting point to mark the neowave patterns.
4. Apply the neowave rules as discussed in “Mastering Elliott Wave” book and forecast the market.
Note
If you want to check Daily or any higher timeframe wave chart use cash chart and if you want to check any other timeframe from 5 seconds to any intraday timeframe then use future's data as suggested by Mr. Glen Neely.

Polynomial Regression Bands w/ Extrapolation of Price [Loxx]Polynomial Regression Bands w/ Extrapolation of Price is a moving average built on Polynomial Regression. This indicator paints both a non-repainting moving average and also a projection forecast based on the Polynomial Regression. I've included 33 source types and 38 moving average types to smooth the price input before it's run through the Polynomial Regression algorithm. This indicator only paints X many bars back so as to increase on screen calculation speed. Make sure to read the tooltips to answer any questions you have.
What is Polynomial Regression?
In statistics, polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modeled as an nth degree polynomial in x. Polynomial regression fits a nonlinear relationship between the value of x and the corresponding conditional mean of y, denoted E(y |x). Although polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear, in the sense that the regression function E(y | x) is linear in the unknown parameters that are estimated from the data. For this reason, polynomial regression is considered to be a special case of multiple linear regression .
Related indicators
Polynomial-Regression-Fitted Oscillator
Polynomial-Regression-Fitted RSI
PA-Adaptive Polynomial Regression Fitted Moving Average
Poly Cycle
Fourier Extrapolator of Price w/ Projection Forecast